物体検出モデル比較 DETR vs YOLOX

※この記事は、物体検出技術の選択に悩む開発者や、技術トレンドに関心のある方向けとなります。初心者には少々難しい話になると思いますが、最後までお読みいただけると幸いです。
皆さん、こんにちは!
LAplustの中村です。
今回は、弊社で使用している物体検出モデルを紹介します。
物体検出とは、画像やビデオ内の物体を識別し、それらの位置を特定することを目的としたコンピュータビジョンの一分野のことで、画像内の物体をバウンディングボックスで囲み、それぞれの物体のクラス(カテゴリ)を識別します。
身近なところでは、監視カメラや顔認識、自動運転の技術に応用されています。
物体検出技術は、個人を特定可能なデータ(例えば、顔認識)を処理する可能性があります。このため、以下の点に注意が必要です。
- 個人情報の取扱い: 使用するデータがGDPRやその他の地域のデータ保護法規制の対象となる場合、個人情報の取り扱いに関して適切な同意を得る必要があります。また、プライバシーポリシーにおいて、どのようなデータをどのように使用するかを明確に記載することが求められます。
- 顔認識技術の使用: 記事に監視カメラや顔認識技術の応用例が言及されています。顔認識技術の使用には特に厳しい規制が存在する場合があり、特定の目的での使用が制限されることもあります。例えば、EUではAI規制案が提案されており、高リスクな使用に対して厳格な要件が設けられる可能性があります。
これから弊社で使用している『DETR』と『YOLOX』という物体検出モデルを比較し、特徴を説明します。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. 概要
2. DETR vs YOLOX
■適用例
■弊社で比較した結果
3. DETR
■特徴
■Transformerとは
4. YOLOX
■特徴
■YOLOとは
5. まとめ
1. 概要
近年、コンピュータビジョンの分野では物体検出技術が目覚ましい進化を遂げています。その中でも、DETR(Detection Transformer)とYOLOXは、それぞれ独自のアプローチで物体検出の新たな地平を開いています。DETRはTransformerベースのモデルで、従来の複雑な物体検出パイプラインを単純化する一方、YOLOXは2021年に公開されたYOLO(You Only Look Once)シリーズのひとつで、速度と精度のバランスをさらに高めたアンカーフリー検出システムを提供します。このブログでは、これら二つの技術を比較し、それぞれの特徴を説明します。

2. DETR vs YOLOX
DETRとYOLOXを比較すると、最も顕著な違いは、それぞれが物体検出タスクに対して取るアプローチの違いです。DETRはエンドツーエンドの学習を実現するためにTransformerを用いる一方、YOLOXはアンカーフリーのアプローチと高速性に焦点を当てています。

・DETR
メリット
①一般的に高い精度を達成することができる。
②複雑なシーンや大きな物体が多い環境に最適。
デメリット
トレーニングにより多くの時間と計算リソースが必要。
・YOLOX
メリット
①リアルタイムアプリケーションに適した高速な検出速度を持つ。
②リアルタイム性が要求されるアプリケーションや小規模なデバイスでの使用に最適。
デメリット
非常に小さい物体の検出には苦戦する可能性がある。
■適用例
DETRとYOLOXは、それぞれ異なるタイプのプロジェクトやアプリケーションで有効です。例えば、DETRは衛星画像の解析や、複雑な背景を持つ画像での細かい物体の検出に使用されています。一方、YOLOXは交通監視システムや、スマートフォンアプリケーションなど、高速な物体検出が必要な環境で好まれています。
■弊社で比較した結果
現在、弊社の機械学習エンジンの一部にDETRとYOLOX両方を組み込んでおり、テスト的に物体検出を比較しました。結果、同数の学習データで学習を行った場合、YOLOXに対してDETRが大幅に検出能力が向上することが分かりました。
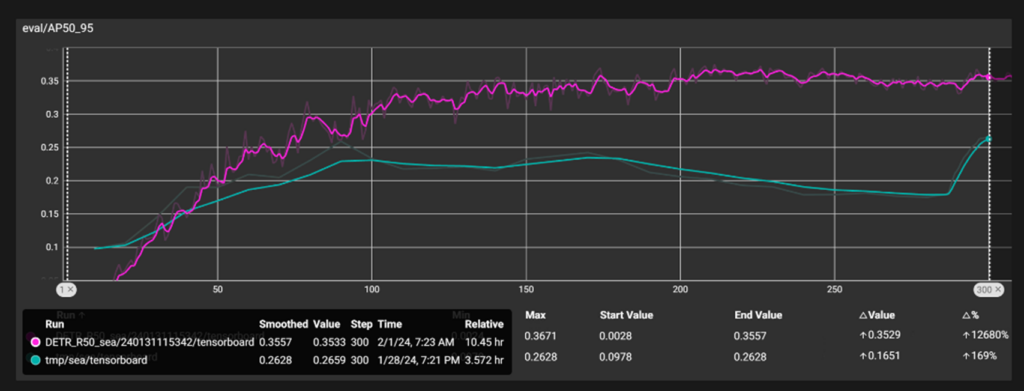
DETRとYOLOXの学習エポックごとのAPの比較(ピンク:DETR 緑:YOLOX)
横軸を学習回数(エポック)、縦軸をAPとしました。上図より、DETR(ピンク)が早い段階でYOLOX(緑)と比較して大きくAP(正しく検出できるかどうか)が出力されていることがわかりました。
YOLOXが最終的に学習させる300エポック目でAP0.25をマークしているのに対して、DETRはおよそ70エポック目にAP0.25を達成していることがわかりました。この差異は検出精度に直結するとともに同じエポック数で学習した際に高い精度をマークできることを示唆しています。
3.DETR
従来の検出システムでは、物体の候補領域を特定し、それぞれを分類するために複数のステップが必要でした。DETRはこのプロセスを単純化し、物体の候補領域を生成する手段としてTransformerを応用することで、複数の処理ステップを一つのネットワークで直接学習することが可能になりました。
■特徴
・エンドツーエンドの学習: 領域提案のステップを必要とせず、入力画像から直接物体のバウンディングボックスとクラスラベルを出力します。これにより、訓練プロセスが単純化され、高い精度を達成することが可能になります。
・Transformerの活用:DETRは、Transformerのアテンションメカニズムを用いて、画像内の全てのピクセル間の関係を学習します。これにより、物体のコンテキスト理解が向上し、精度の高い検出が可能になります。
・セットベースの予測:DETRは、予測された物体を固定長のセットとして扱い、ハンガリアンアルゴリズムを使用して最適な予測セットを見つけ出します。これにより、予測の重複を回避し、各物体を一意に識別します。
DETRは物体検出タスクにおいて高いパフォーマンスを示します。特に複雑なシーンや小さな物体の検出においてその効果を発揮します。また、そのエンドツーエンドのアプローチと単純化された訓練プロセスは、物体検出分野における新たな方向性を示しています。
■Transformerとは
Transformerは、主に自然言語処理(NLP)分野で革命を起こしたモデルアーキテクチャです。このモデルは、従来のリカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)に代わるものとして設計され、大規模なテキストデータセットの学習において顕著な効果を発揮しました。

◆特徴
・アテンションメカニズム:Transformerの核となるのは、セルフアテンション(自己注意)メカニズムです。これにより、入力シーケンス内の任意の位置間の依存関係を直接モデル化し、文脈理解を深めます。
・並列処理の強化:RNNが時系列データを順番に処理するのに対し、Transformerは入力データを一度に処理することができます。これにより、訓練速度が大幅に向上します。
・スケーラビリティ:Transformerは非常に大規模なデータセットとモデルサイズに適応する能力があり、大量のパラメータを持つモデルを効率的に訓練することが可能です。
◆応用
Transformerは、多くのNLPタスクやモデル(BERT、GPT、T5など)の基礎となりました。また、音声認識や画像処理など、NLP以外の分野においても応用されています。そのスケーラビリティと高いパフォーマンスにより、現代のAI研究において非常に重要なモデルアーキテクチャとなっています。
4. YOLOX
YOLOXはアンカーフリー検出を採用し、以前のYOLOバージョンに比べて精度と性能を大幅に向上させています。アンカーボックスを使用しないことで、モデルはより柔軟に物体の形状とサイズに適応でき、検出精度を向上させます。また、スケーラブルなアーキテクチャにより、様々なサイズのデバイスやアプリケーションに容易に適用可能です。
■特徴
・アンカーフリー
YOLOXはアンカーフリー(anchor-free)アプローチを採用しています。これは、以前のYOLOバージョンで使用されていたアンカーボックス(事前に定義された参照ボックス)に依存せず、オブジェクトの位置とサイズを直接予測する方法です。この変更により、モデルの設計が単純化され、異なるスケールやアスペクト比を持つオブジェクトに対する柔軟性が向上しました。
・Decoupled Head
YOLOXは、オブジェクトのクラス分類とバウンディングボックスの回帰を行うために、デカップリングされたヘッド(decoupled head)を採用しています。これにより、それぞれのタスクに特化した処理が可能になり、検出性能が向上します。
・ストロングデータ拡張
YOLOXは、トレーニング中に複数の強力なデータ拡張技術を使用しています。これにより、モデルがさまざまな条件や変化に強い汎用性を持つようになります。例えば、MixUpやMosaicといった技術が利用され、トレーニングデータセットの多様性を大幅に高めています。

・スケーラビリティ
YOLOXは、小型デバイスから高性能サーバーまで、幅広いプラットフォームで効率的に動作するように設計されています。モデルのサイズと計算コストを調整することで、様々な環境や要件に合わせたデプロイメントが可能です。
YOLOXは、高速かつ正確なオブジェクト検出のための進歩した技術として注目されており、アプリケーションや研究での使用が期待されています。その効率性と性能のバランスにより、リアルタイムビデオ分析、自動運転車、監視システムなど、多岐にわたる分野で利用されています。
■YOLOとは
「YOLO(You Only Look Once)」は、画像内の物体検出に使われるコンピュータビジョンのためのモデルアーキテクチャです。この手法は、画像を単一のニューラルネットワークを通して一度だけ処理することで、物体の検出と分類を同時に行います。
◆特徴
・高速性:処理過程がシンプルなため、リアルタイムの物体検出に非常に適しています。特に、車載カメラや監視カメラなどのリアルタイムでの物体検出が求められる用途に有効です。
・背景誤認識の低減:物体が存在しない領域に対する誤検出が少ないという特徴があります。これは、全画像を通して物体の検出を行うため、背景と物体の区別がより明確になるためです。
◆バージョン
YOLOは初期バージョンから改良が重ねられ、バージョンごとに精度の向上、速度の改善、より複雑なシーンでの検出能力の向上を図り、進化を続けています。
5. まとめ
DETRとYOLOXは、物体検出の分野における重要な進歩を代表しています。それぞれが持つユニークな特徴とアプローチは、特定のニーズや状況に応じて、開発者が適切な選択をするのに役立ちます。物体検出技術の選択は、プロジェクトの要件、リソースの利用可能性、そして最終的なアプリケーションの目的に大きく依存します。
この記事を通じて、皆様がそれぞれの技術の特徴を理解し、各プロジェクトに最適な物体検出モデルの選択をするための参考になれば幸いです。
最後に弊社の物体検出サービス『LAplust Eye』を紹介します。LAplust Eyeは物体検出によって人の目視作業を代替するサービスです。既存の生産ラインや現場の協働ロボットに部品として取り入れることで生産性の向上を目的に提供を開始したサービスです。
ご興味がおありでしたら、お問い合わせください。活用事例を踏まえてご紹介させていただきます。
難しい内容になり長くなってしまいましたが、最後までお読みいただきありがとうございました。