DETRのセグメンテーションモデル

※この記事は、物体検出技術に関心のある方向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回は「DETRのセグメンテーションモデル」を紹介します。
前回の技術ブログ「DETR vs YOLOX」で紹介した「DETR」は覚えていらっしゃいますか?
覚えてないよ、まだ読んでないよ、という方はこちらからお読みいただきたいです。
※今回のブログは、前回の内容をある程度把握できていないと理解が深まりにくい内容となりますので、ご了承ください。
その「DETR」のセグメンテーションモデルが、高精度の物体検出モデルとして注目されており、弊社でも独自の機械学習ライブラリに組み込んでいます。
初心者には少々難しい話になると思いますが、是非最後までお読み下さい。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1.背景
2.DETRのセグメンテーション能力
3.DETRの利点と課題
■利点
■課題
4.まとめ
1.背景
物体検出技術は、画像内のオブジェクトを識別し、位置を特定することにより、コンピュータビジョンの領域で不可欠な役割を果たしています。しかし、単にオブジェクトを識別するだけでなく、それぞれの正確な形状や境界を理解することが、多くの応用で求められています。ここで重要になるのが「セグメンテーション」です。
セグメンテーションは、オブジェクトの精密な輪郭を描き出し、画像内の各ピクセルがどのオブジェクトに属するかを分類します。この精度の高い分析が、自動運転車、医療画像解析、監視システムなど、多岐にわたるアプリケーションにおいて重要な役割を果たしています。
近年、DETR(Detection Transformer)という新しいモデルが登場し、物体検出のパラダイムに革命をもたらしました。従来の手法とは異なり、DETRはTransformerアーキテクチャを利用して物体検出を直接的かつ効率的に行います。このアプローチにより、複雑な背景や重なり合うオブジェクトが存在するシーンでも、より正確な物体検出が可能になります。
さらに、DETRはセグメンテーションタスクにも応用されており、オブジェクトの検出だけでなく、その形状やサイズをより詳細に把握することが可能になっています。
弊社は、社会課題となっている「人手不足」の解消に向けて、目視工程に着目し、目視の代替として「LAplust Eye」という物体検出エンジンを提供しており、日々改善を重ねています。
この「LAplust Eye」にYOLOXに加えDETRの物体検出モデルを組み込んだことにより、高精度の物体検出を可能としています。
今回、新たにDETRのセグメンテーションモデルを組み込み、更なる高精度の物体検出に繋がりました。
この技術を高め普及することで、人手不足を解消する一助になりたいとメンバー全員が思っています。
また、我々のビジョンは「ものづくりでたべものづくり」であり、「高生産性栽培ハウス」を実現するために日々技術を積み重ねており、人々の営みに欠かせない「食」での社会貢献を目指しています。

このブログでは、DETRがどのように物体検出とセグメンテーションの領域で新たな基準を設定しているのかを掘り下げていきます。従来の手法との違い、DETRのセグメンテーション能力の具体的なメリット、そして現在の課題について詳しく解説していきます。
2.DETRのセグメンテーション能力
DETRは、物体検出を目的とした深層学習モデルであり、画像内の物体を識別し、それぞれの位置を特定することができます。しかし、DETRの真の力は、単に物体を検出することだけにとどまりません。この革新的なモデルは、セグメンテーションタスクにおいても同様に卓越した性能を発揮します。
セグメンテーションとは、画像をピクセルレベルで解析し、各ピクセルがどの物体に属するかを識別するプロセスです。これにより、物体の正確な形状、大きさ、そして位置が明らかになります。
DETRは、Transformerのアーキテクチャを活用して、セグメンテーションを行います。このモデルは、画像全体を一度に処理し、物体の「理解」を深めるために、全体的なコンテキスト情報を利用します。従来の手法では、ローカルな特徴や切り出されたパッチを基に物体を検出し、それから別途セグメンテーションを行っていました。
しかし、DETRでは、物体検出とセグメンテーションが一つの統合されたフレームワーク内で同時に行われます。これにより、プロセスが大幅に簡素化され、さらに精度の高い結果が得られるようになります。
実際のセグメンテーション結果を見ると、DETRは複雑なシーンや重なり合う物体が存在する場合でも、個々の物体を正確に識別し、その形状を精密に描き出しています。これは、例えば、人込みの中の個々の人物や、自然の風景の中の植物や建物など、さまざまなシーンで有効です。
実際に弊社で実装し、確認した結果が以下になります。左が元画像、右がセグメンテーションした画像です。
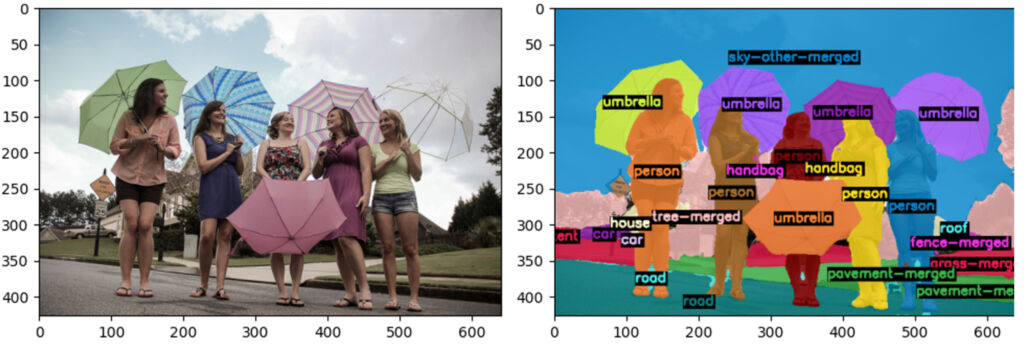
重なり合った物体でも正確に検出できていることがわかります。
DETRによるセグメンテーションの精度は、自動運転車のナビゲーション、医療画像の解析、さらには小売業の在庫管理に至るまで、多岐にわたる応用が期待されています。
DETRのセグメンテーション能力は、物体検出と画像解析の分野において、新たな標準を確立しようとしています。このモデルが解き明かす画像の詳細と精度は、従来のアプローチでは達成が難しかったレベルにあります。この進歩により、よりリアルタイムで正確なビジョンベースのアプリケーションの開発が可能になり、多くの業界での革新が期待されています。
3.DETRの利点と課題
DETRは物体検出とセグメンテーションの分野において多くの注目を集めていますが、このモデルが持つ利点と同時に、解決すべきいくつかの課題も存在します。
■利点
1.統合されたフレームワーク: DETRは、物体検出とセグメンテーションを単一のフレームワークで行うことができる最初のモデルの一つです。これにより、モデルの複雑性が軽減され、トレーニングと推論のプロセスが簡素化されます。
このプロセスの簡素化は、お客様自身がお客様の現場や課題に合った推論モデル作成を簡素化できることにつながります。
弊社では、難しく見えるCUIベースのインターフェースからユーザーフレンドリーなGUIベースでの操作を可能とし、特別なITスキルが無くてもAIを作成しお客様の課題にあった推論モデルを簡易に生み出し続けられることを目指しています。
2.グローバルなコンテキストの活用: Transformerアーキテクチャを採用しているため、DETRは画像全体のコンテキストを考慮して物体を検出します。これにより、特に複雑なシーンや重なり合うオブジェクトが存在する場合に、より正確な検出が可能になります。
弊社が目指している「高生産性栽培ハウス」においては、収穫物の収穫可否判断にDETRを用いることで、重なり合った収穫物の検出精度向上を実現できます。
3.ノイズの少ないセグメンテーション: DETRは、ピクセルレベルでの精密なセグメンテーションを実現し、物体の正確な輪郭を描き出します。これは、特に精密な画像解析が求められる医療や自動運転車の分野で大きな利点となります。
弊社が目指している「高生産性栽培ハウス」においては、収穫時の収穫物境界検出にDETRを用いることで、収穫物の掴み方ミスでのキズ発生による廃品削減を実現できます。
■課題
1.トレーニング時間: DETRはトレーニングに時間がかかるという大きな欠点があります。この長いトレーニング時間は、特にリソースが限られている状況での使用には不便です。
この課題は近年目覚ましい進化を遂げている学習用ハードウェアを取り揃え、最適化したアルゴリズムを構築することで解消する余地があります。
2.データセットの要件: 高い性能を発揮するためには、大量のラベル付きトレーニングデータが必要です。これは、利用可能なデータが限られている特定のアプリケーションでは問題となる可能性があります。
この課題はすでに解消されており、すでに利用者は少量のデータのみで高い精度がでるように最適化されています。通常、数千・数万枚のデータが必要なケースでも数十・数百のデータで学習を行うことで十分な性能を発揮できる技術を実現しました。今後も改善を続けていきます。
3.一般化能力の問題: 一部のシナリオでは、DETRが過剰に特化しすぎてしまい、見たことのない新しいシーンやオブジェクトに対してはうまく機能しないことがあります。この一般化能力の欠如は、実世界の応用において大きな課題となります。
この課題もすでに解消されており、すでに利用者はこの課題を特別に意識せずに利用できるレベルにまで来ています。詳細は別の記事でも記載を行っていきたいと思います。
DETRの将来は明るいものがありますが、これらの利点を最大限に活かし、同時に課題を克服するためには、継続的な研究と改善が必要です。特にトレーニング時間の削減と一般化能力の向上は、このモデルが広く採用されるための鍵になると思います。
これらの課題をお客様自身が特別に意識することなく克服できるよう弊社では日々、研究開発と利用者に快適にご利用いただくための仕組みづくりを進めております。
4.まとめと今後の展望
このブログで紹介したように、DETRは、物体検出とセグメンテーションの分野において、多くの可能性を秘めた革新的なアプローチを提供しています。セグメンテーション能力において特に顕著な利点を示し、画像解析の精度と効率を向上させることに成功しています。統合されたフレームワーク、グローバルなコンテキストの利用、そしてノイズの少ないセグメンテーションは、DETRを特に魅力的な選択肢にしています。
しかし、長いトレーニング時間、大量のデータへの依存、そして一般化能力の問題といった課題は、今後の研究で克服すべき重要なポイントです。これらの課題を解決することにより、DETRはさらに幅広いアプリケーションでの使用が可能になると期待されます。
今後の展望として、弊社はDETRのアルゴリズムをさらに深堀り・応用し、トレーニングプロセスの高速化、データ効率の向上、そして一般化能力の強化を進めます。これらの改善により、DETRはリアルタイムアプリケーションでの使用や、データが限られた環境での効率的な運用が可能になります。また、セグメンテーションの精度のさらなる向上は、製造業・農業など、さまざまな分野での応用を促進します。
DETRの発展は、コンピュータビジョンの分野における新たな標準を確立し、画像解析の可能性を広げることに寄与することは間違いありません。
背景で触れました弊社の物体検出サービス『LAplust Eye』を紹介します。LAplust Eyeは物体検出によって人の目視作業を代替するサービスです。既存の生産ラインや現場の協働ロボットに部品として取り入れることで生産性の向上を目的に提供を開始したサービスです。
ご興味がおありでしたら、お問い合わせください。活用事例を踏まえてご紹介させていただきます。
難しい内容になりましたが、最後までお読みいただきありがとうございました。