機械学習システムでExif情報を考慮しない理由

※この記事は、機械学習で推論を実施する初心者のエンジニア向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回のテーマは、「機械学習システムでExif情報を考慮しない理由」です。
前回の技術ブログ「物体検出タスクにおけるExif情報の落とし穴」で、LAplustの機械学習システムは、意図的にExif情報を考慮しないシステムにしていることを記述していましたが、覚えていらっしゃいますか?
覚えてないよ、まだ読んでないよ、という方はぜひこちらからお読みいただきたいです。
※今回のブログは、前回のブログをお読みいただいた前提で執筆していますので、ご了承ください。
LAplustの機械学習システムは、Exif情報があった場合でも、意図的に画像読み込み時に正位置となるように設計しています。
このように設計した理由は、システム全体の設計思想やAI業界全体としての考え方が関連しています。
なぜExif情報を考慮しないのだろうかと思われる方もいらっしゃると思いますので、その理由をブログにしました。
このブログを読むことで、なぜExif情報を考慮しない機械学習システムにしているのかという疑問が解決されれば幸いです。
これから機械学習システムでExif情報を考慮しない理由について記載していきます。
是非最後までお読みください。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. 機械学習システムでExif情報を考慮しない理由
2. データを揃える段階で行うExif情報の処理
3. まとめ
1. 機械学習システムでExif情報を考慮しない理由
前回の技術ブログで、LAplustの機械学習システムは、意図的にExif情報を考慮しないシステムにしていることを記述しました。
また、他社の機械学習システムについて調べてみると、有名なGoogle VisionもExif情報を考慮していないことがわかります。
参考元:https://gigazine.net/news/20191208-python-exif-orientation/
このようにLAplustだけではなく、Googleの機械学習システムも意図的にExif情報を考慮していません。
PyTorchというPythonのオープンソース機械学習ライブラリも画像のExif情報を直接読み取るための機能は提供しておらず、機械学習においては、Exif情報を考慮しないことが一般的です。
LAplustの機械学習システムが、意図的にExif情報を考慮しないシステムにしている理由は以下になります。
- 学習時間を短縮するため
現代において機械学習は、大量のデータをより高速に処理することが重要事項の1つとなっており、高速処理できる機械学習システムを構築する必要があります。
そのため1ミリ秒でも早く画像を読み込み、学習時間を短縮する必要があるため、やらなくてもいい処理はやらないようにシステム設計をしています。 - データセットの一貫性を保証するため
機械学習ライブラリは、データを与えられて学習しモデルを作ります。
もし与えられたデータセットを機械学習ライブラリが変更してしまうと、データセットの一貫性を保証できなくなります。
Exif情報を考慮し整形することや他のデータ加工を機械学習ライブラリがやってしまうと、機械学習ライブラリに与えられた情報がどんどん変わってしまい、元々の情報が分からなくなってしまいます。
データセットを意図した形に整えるのは、学習開始前に行う「前処理」よりもさらに前の「データを整える」段階で行うことが、データセットの一貫性を保証するためには必要となります。 - ノイズを除去しモデルの性能向上を図るため
Exif情報は、画像の内容そのものに直接関係する情報ではありません。
機械学習モデルが画像の特徴を学習する際には、ピクセルデータや画像のパターンが重要です。
Exif情報がモデルの性能に与える影響は限定的ではありますが、ノイズとなる可能性が高いです。
そのため、Exif情報を考慮しないことで、モデルの学習に集中でき、性能の向上が期待できます。
2. データを整える段階で行うExif情報の処理
前項にて、データセットを意図した形に整えるのは、学習開始前に行う「前処理」よりもさらに前の「データを整える」段階で行うことが必要であると記述しました。
機械学習の流れは以下のようになります。
データを収集する
↓
データを整える ←ここでExif情報の処理(特に画像の向きの処理)を実施してください。
↓
データセットを準備する
↓
アノテーションを実施する
↓
学習前の前処理を行う
↓
学習する
↓
学習後の後処理を行う
↓
学習モデルを評価する
↓
推論する
これからExif情報の処理(特に画像の向きの処理)について説明します。
- Exif情報の「Orientation」の値を変更する
Exif情報の中で「Orientation(向き)」の値が画像の向きを表しています。
値と画像の向きの対応表は以下になります。
引用元:https://qiita.com/yoya/items/4e14f696e1afd5a54403
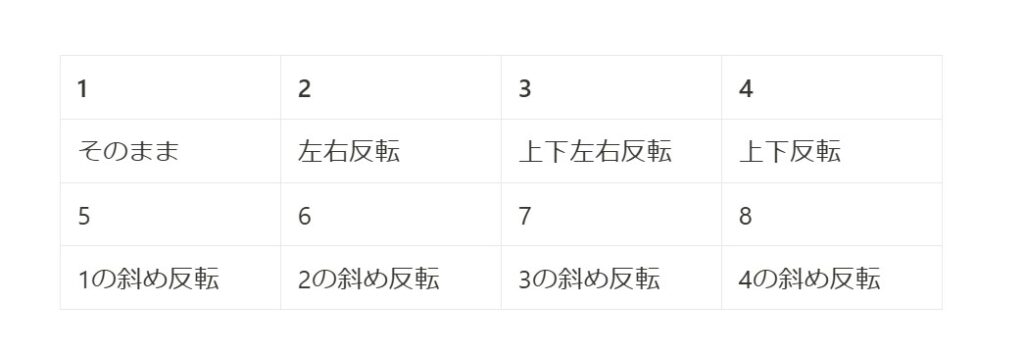
文字だけではなく、図で示します。
Orientation操作をされた画像が以下の配置であるとき
引用元:https://qiita.com/yoya/items/4e14f696e1afd5a54403

元画像の早見表は以下になります。
引用元:https://qiita.com/yoya/items/4e14f696e1afd5a54403
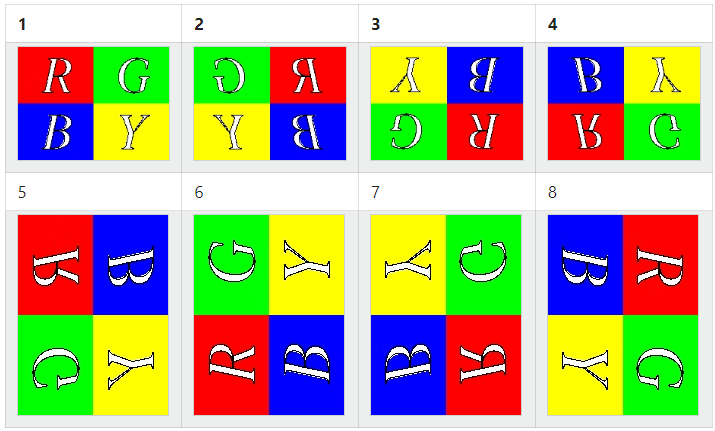
「Orientation」の値が「1」の場合は正位置となります。
下記のフローチャートは「Orientation」の値を「none」もしくは「1」に変更する際の例になります。
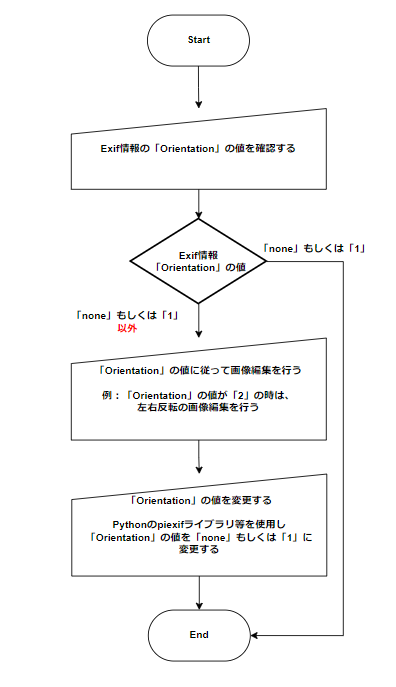
ここまで読み進んでいただいた方は、具体的に「Exifの適切な処理」を実現するためにはどうすればいいのか?という興味を持たれていることでしょう。
ここでは、一例としてPythonのpiexifライブラリ等を使用し、Exif情報のOrientationの値を1(正位置)に変更するプログラムの例を紹介します。みなさんのプロジェクトで実装される際の参考になれば幸いです。
※事前準備として、Pillowとpiexifをインストールする必要があります。
- Pillow: 画像の読み込みと保存を行うためのライブラリ
- piexif: Exif情報の読み込みと操作を行うためのライブラリ
pip install pillow piexif
プログラムの動作は以下になります。
画像を取得する
↓
Exif情報を取得する
↓
Orientationの値を1に変更する
↓
Exif情報をバイナリデータに変換する
↓
画像を保存する際に新しいExif情報を付加する
import os
from PIL import Image
import piexif
input_directory = "path_to_your_input_directory" # 入力ディレクトリのパス
output_directory = "path_to_your_output_directory" # 出力ディレクトリのパス
def change_orientation_to_1(image_path, output_path):
# 画像を開く
img = Image.open(image_path)
# Exif情報を取得
if 'exif' in img.info:
exif_dict = piexif.load(img.info['exif'])
else:
exif_dict = {"0th": {}, "Exif": {}, "GPS": {}, "1st": {}, "thumbnail": None}
# Orientationの値を1に変更
exif_dict['0th'][piexif.ImageIFD.Orientation] = 1
# Exif情報をバイナリデータに変換
exif_bytes = piexif.dump(exif_dict)
# 画像を保存する際に新しいExif情報を付加
img.save(output_path, "jpeg", exif=exif_bytes)
def main():
# 入力ディレクトリ内のすべてのファイルを処理
for filename in os.listdir(input_directory):
# 画像ファイルかどうかをチェック
if filename.lower().endswith(('.jpg', '.jpeg')):
input_image_path = os.path.join(input_directory, filename)
output_image_path = os.path.join(output_directory, filename)
# Orientationを1に変更
change_orientation_to_1(input_image_path, output_image_path)
print(f"Processed {filename}")
main()
※入力ディレクトリと出力ディレクトリのパスは、皆様が使用するディレクトリのパスに変更してください。
プログラムの実行結果です。
まず、プログラム実行前の画像とOrientation情報です。
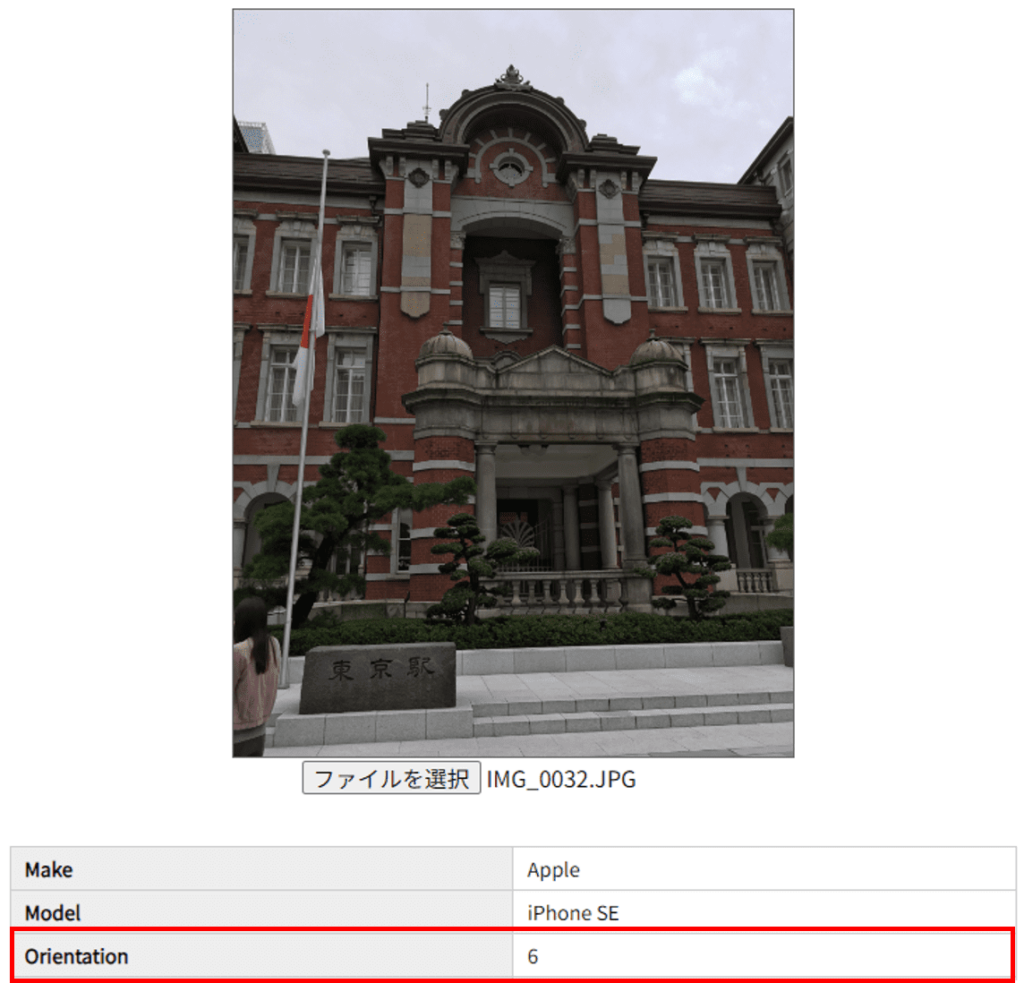
「Orientation」の値が「6」となっています。
Orientation操作をされた画像が以下の配置と同じとなっており、早見表と対応しています。
引用元:https://qiita.com/yoya/items/4e14f696e1afd5a54403

早見表で元画像の表示を確認します。
引用元:https://qiita.com/yoya/items/4e14f696e1afd5a54403
早見表を確認すると、「Orientation」の値が「6」の元画像は、表示画像を時計回りに270度回転された画像であることがわかります。
そして、プログラム実行後の画像とOrientation情報です。
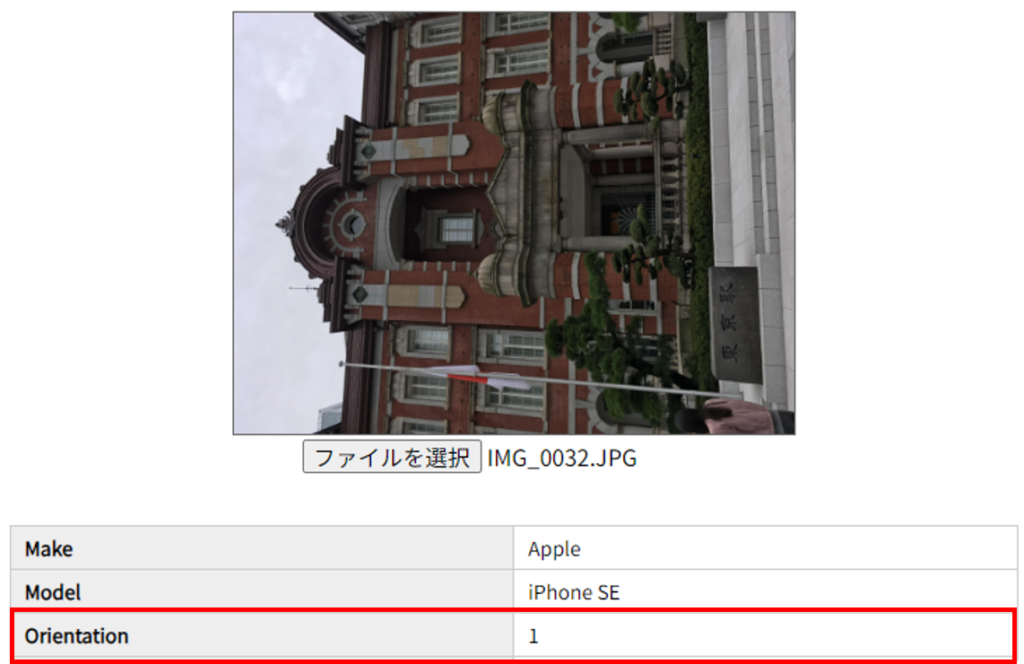
「Orientation」の値が「1」になりました。
画像の向きも変わっていますね。
このように「Orientation」の値を「1」に変更することができました。
前回の技術ブログでLAplustは、Exif問題につまづいた時のことを記載しました。
その時のケースでは、Exif情報は不要かつ画像枚数が比較的少数でしたので、下記の対応を実施し再度学習を行いました。
①Pythonのpiexifパッケージを使用し、Exifデータから画像回転情報(「向き」)を削除
②GIMPというGUIの画像編集ソフトウェアを使用し、画像編集を実施(画像回転情報と同様の回転を行い保存)
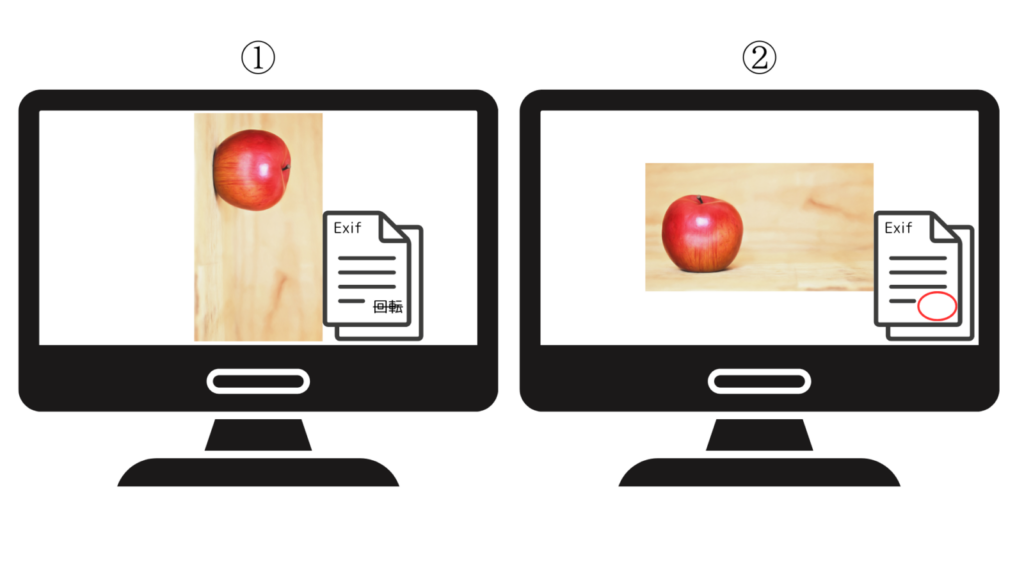
※このケースでは、Exif情報が不要かつ画像枚数が比較的少数であったため、①と②の対応を行いましたが、ベストな手法ではありません。
大量の画像枚数を処理する場合のことを考えると、Exif情報編集(特に画像の向き)は人間が行わず、プログラムで処理を完結させることがベストだと思われます。
またLAplustは、機械学習システム側にも対策を行いました。
学習前のデータ読み込み時に、画像を回転するExifデータが格納されている場合は注意喚起を行う前処理を導入しました。
※Exif情報の処理はデータを整える段階で行うことが基本であるため、機械学習システムでは注意喚起のみ行うようにしています。
以下は、LAplustで実装しているソースコードの一部です。
Exif情報の「orientation」の値が「none」もしくは「1」以外の場合は、注意喚起を行うようにしています。
from PIL.Image import Image
def check_validity(img):
assert isinstance(img, Image)
exif = img.getexif()
if exif is not None:
# Exifで回転されているものは意図した回転方向で全工程で一貫して
# 扱われていない可能性があるのでエラーとする
orientation = exif.get(274)
assert \
orientation is None or orientation == 1, \
"Image has orientation Exif, remove it for consistency."
3. まとめ
今回のブログは、機械学習システムでExif情報を考慮しない理由とデータを揃える段階で行うExif情報の処理について記述しました。
機械学習システムは、学習時間の短縮やデータセットの一貫性を保証するため、Exif情報を考慮しない設計となっています。
また、データセットを意図した形に整えるのは、学習開始前に行う「前処理」よりもさらに前の「データを揃える」段階で行うことが必要です。
Exif情報の処理(特に画像の向き)については、アノテーションを実施する前に行うことが重要です。
- 「人間はデータセットを意図した形に整える」
- 「機械学習システムは学習をより高速で行う」
このように仕事を分担することで、高精度の機械学習の結果が得られるようになります。
このブログが皆様にとって有益な情報となれば幸いです。
LAplustではChatGPTをはじめとした「生成AI」の機能を飛躍的に向上させたTransformerを画像や物体検出に応用し、高精度な「人の目視と判断」を提供するLAplust Eyeを開発しております。
- 製品外観検査の省力化・省人化
- 出荷前の不良品検出
- 生態調査の半自動化
など省人化と活人化を実現したい現場の課題について声をお聞かせいただけると幸いです。
上記のような課題をお持ちであったりLAplust Eyeにご興味をお持ちいただけましたら、ぜひ、お問い合わせください。
最後までお読みいただきありがとうございました。