CLIPの紹介とLAplustのCLIP実装

※この記事は、機械学習モデルを実装する初心者のエンジニア向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回のテーマは、「CLIPの紹介とLAplustのCLIP実装」です。
CLIPは、画像生成技術や物体検出技術と組み合わせると、文章から画像を生成できたり、数万種類の物体検出ができるようになることから「基盤モデル」と呼ばれます。
今回LAplustは、新しい機械学習モデルとしてCLIPを実装し、物体検出技術を組み合わせることで、数万種類の物体検出ができるようになったり、面倒なアノテーション作業を半自動で済ませられるようになったり、とメリットが多分にあるため、これをLAplust Eyeに応用する試みを行っております。
このブログが、皆様のCLIPの基礎知識習得に貢献することができ、LAplustのCLIP実装について紹介できる場となれば幸いです。
これからCLIPの紹介とLAplustのCLIP実装について記載していきます。
是非最後までお読みください。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. CLIPとは
2. LAplustのCLIP実装
3. まとめ
1. CLIPとは
CLIP(Contrastive Language-Image Pre-training)は、OpenAIが開発した画像と文章をペアとして学習する機械学習モデルです。
従来の画像認識モデルとは異なり、CLIPはラベル付きデータに依存せず、大規模なインターネットから収集された画像と文章のペアを利用して学習します。
CLIPの学習方法
CLIPは以下のような手法で学習します。
- データ収集
インターネット上の大規模なデータセットから画像とその説明文を収集します。(4億組) - モデルの構成
CLIPは、「画像エンコーダ」と「テキストエンコーダ」の二つで構成されています。
画像エンコーダには、画像処理で使われる特徴抽出モデル(ResNetやVision Transformer)が使用され、画像を画像特徴ベクトルに変換します。
テキストエンコーダには、自然言語処理で使われる特徴抽出モデル(Transformer)が使用され、文章を文章特徴ベクトルに変換します。 - 学習
まず、画像特徴ベクトルと文章特徴ベクトルの類似度を計算します。(コサイン類似度)
その後、画像と文章のペアが一致する場合には類似度を高く、一致しない場合には類似度を低くなるように学習します。
このようにして、画像と文章のペアを効果的に関連付けることができます。
下図の(1)が学習部分になります。
引用元:https://github.com/openai/CLIP
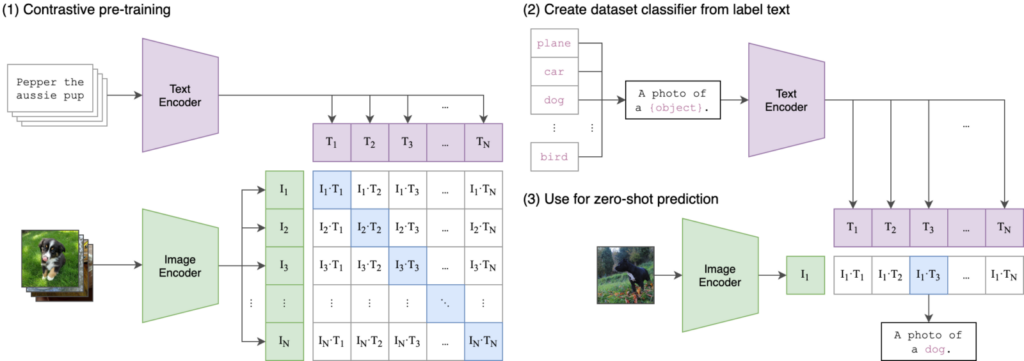
CLIPの推論方法
CLIPには以下のような推論方法があります。
①複数の候補文を用意し、最も近いものを当てる
- 推論画像に対し、候補文を用意します。(候補文はいくらあってもOK)
- 画像、文章をそれぞれ「画像エンコーダ」、「テキストエンコーダ」に入力し、特徴ベクトルを出します。
- 各候補文の特徴ベクトルと画像の特徴ベクトルの類似度を計算し、類似度が最も高くなる候補を選びます。
下図の(2)と(3)が推論部分になります。
引用元:https://github.com/openai/CLIP
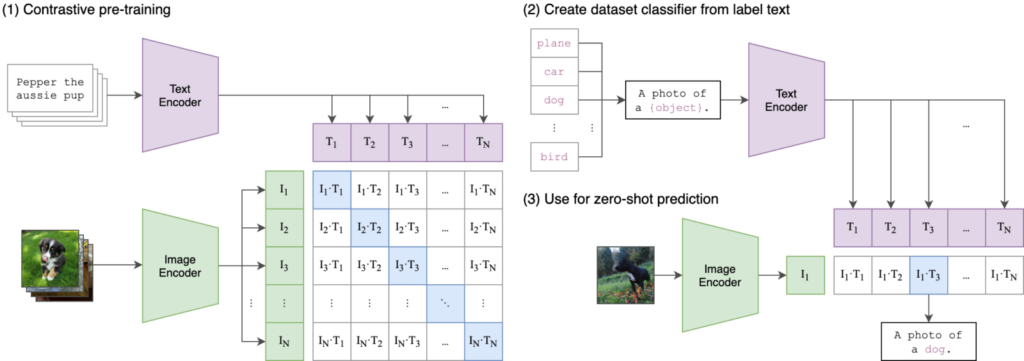
②文章生成モデルと組み合わせて画像から文章を生成する
- 推論画像を「画像エンコーダ」に入力し、特徴ベクトルを出します。
- この特徴ベクトルを文章生成モデル(機械翻訳等で使われる自然言語を生成するモデル)に入力し、文章を生成します。
CLIPの応用
CLIPは極めて多様な画像特徴を抽出でき、文章との対応がとれるため、様々な応用が可能となります。
例えば、以下のことが可能となります。
1.画像生成技術と組み合わせると、文章から画像を生成できる
2.物体検出技術と組み合わせると、数万種類の物体検出ができる
このように様々な応用に使えることから、CLIPは「基盤モデル」と呼ばれます。
1は様々なサービスで既に応用展開されており、なじみがある方も多いかもしれません。
LAplustでは「2.物体検出技術と組み合わせると、数万種類の物体検出ができる」をLAplust Eye
に応用する試みを行っております。
2. LAplustのCLIP実装
今回LAplustは、新しい機械学習モデルとしてCLIPを実装しました。
「1枚の画像と複数の文章を機械学習モデルに与えたとき、どの文章が画像とより関連しているか」を推論するようになっています。
少しだけですが紹介します。
次のような入力画像と入力文章を与えました。
- 入力画像
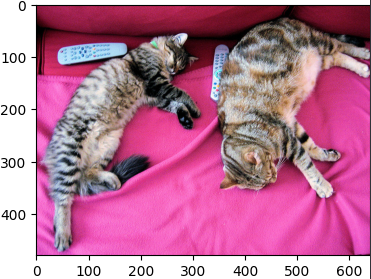
- 入力文章

下記が出力結果です。

「cat」を選択できていることがわかります。
実際、画像には複数の猫が写っているので、「a cat」の他に「cats」を加えてみました。

より画像に適した文章が選択されていますね。
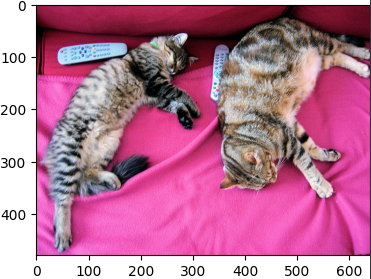
また、リモコンも写っているのでリモコンを追加しました。

「cats」と「remotes」が複合した文章を選択できています。
場所の情報を追加しました。

いい感じですね。
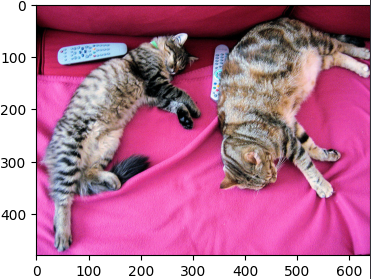
色の情報を追加しました。

なんと色まで選択できてます。
このように、より画像に適した文章が選択されるようになっています。
これらを応用し、最終的には「物体検出モデルのアノテーション」をLAplust Eyeの機能として実現することを目指しています。
これが実現することによって、
- インターネット上の大規模なデータセットで学習データを収集し学習するため、新たに「アノテーション」を実施するケースが減り、工数を削減できる
- LAplust Eyeは、学習したことが無い分類を推論することができる(ゼロショット学習) 例:LAplust Eyeに「シマウマ」の画像を入力すると、LAplust Eyeが「シマウマ」という分類を学習したことがなくても、学習結果に「白黒縞の猫」や「茶色の馬」がある場合、「白黒縞の馬」と分類することができる
といったようなメリットを生み出せると考えています。
3. まとめ
今回のブログは、CLIPの紹介とLAplustのCLIP実装について記載しました。
CLIPは、画像と文章をペアとして学習する機械学習モデルで、大規模なデータセットを「画像エンコーダ」と「テキストエンコーダ」でそれぞれ特徴ベクトルに変換します。
その後、それぞれの特徴ベクトルの類似度を計算し、画像と文章のペアが一致する場合には類似度を高く、一致しない場合には類似度を低くなるように学習します。
また、LAplustが実装したCLIPにて、「1枚の画像と複数の文章を機械学習モデルに与えたとき、どの文章が画像とより関連しているか」の推論結果を確認できたかと思います。
これからLAplustは、今回実装したCLIPをLAplust Eyeに応用できるように開発を進め、皆様により良い技術を提供できるよう邁進していきます。
このブログが皆様にとって有益な情報となれば幸いです。
LAplustではChatGPTをはじめとした「生成AI」の機能を飛躍的に向上させたTransformerを画像や物体検出に応用し、高精度な「人の目視と判断」を提供するLAplust Eyeを開発しております。
- 製品外観検査の省力化・省人化
- 出荷前の不良品検出
- 生態調査の半自動化
など省人化と活人化を実現したい現場の課題について声をお聞かせいただけると幸いです。
上記のような課題をお持ちであったりLAplust Eyeにご興味をお持ちいただけましたら、ぜひ、お問い合わせください。
最後までお読みいただきありがとうございました。