SAMの紹介とアノテーション作業の自動化構想

※この記事は、機械学習に関心がある初心者のエンジニア向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回のテーマは、「SAMの紹介とアノテーション作業の自動化構想」です。
SAMは、Meta社が開発した機械学習のセグメンテーションモデルで、ポイントやバウンディングボックスの入力プロンプトからオブジェクトマスクを生成し、画像内のすべてオブジェクトに対してセグメンテーションを行います。
このSAM は膨大な画像とマスクで構成されたデータセットで事前にトレーニングしたモデルとなっているため、ユーザーが様々なセグメンテーションを実施する際、新たに学習せずとも(ゼロショット学習) 高精度のセグメンテーションを実現できます。
実際に公式サイトのデモをやってみたことを記載していますので、この記事を参考にしていただき、皆様も公式サイトのデモをやってみることをおすすめします。
また、LAplustが今後実装を進める「CLIP+SAM」によるアノテーション作業の自動化構想についても記載しています。
アノテーション作業の自動化に興味がある方にとって、有益な情報になると思います。
是非最後までお読みください。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. SAMとは
2. 「CLIP+SAM」によるアノテーション作業の自動化構想
3. まとめ
1. SAMとは
SAM(Segment Anything Model)は、Meta社が開発した機械学習のセグメンテーションモデルです。SAMは、ポイントやバウンディングボックスの入力プロンプトからオブジェクトマスクを生成し、画像内のすべてオブジェクトに対してセグメンテーションを行います。
1,100万枚の画像と 11 億個のマスクのデータセットで事前にトレーニングされているため、ユーザーが様々なセグメンテーションを実施する際、新たに学習せずとも(ゼロショット学習) 高精度のセグメンテーションを実現できます。
実際に公式サイトのデモをやってみました。
画像内のセグメンテーションしたい物体(ここでは犬とする)をポイントやバウンディングボックスで指定すると、犬を認識し、犬の形にセグメンテーションを行ってくれます。
セグメンテーション前の画像
引用元:https://segment-anything.com/demo

ポイントで指定した場合
引用元:https://segment-anything.com/demo

バウンディングボックスで指定した場合
引用元:https://segment-anything.com/demo

上の2枚のセグメンテーションされた画像は、ポイントやバウンディングボックスで犬を指定しただけです。
あとはSAMがセグメンテーションを行ってくれました。(青枠でセグメンテーションしています)
SAMのセグメンテーションの精度が非常に高いことに驚きました。
また、この機能を無料で使用できることにも魅力を感じました。(モデルのライセンス:Apache-2.0)
LAplustでは、SAMのセグメンテーション機能をLAplust Eyeに搭載し、推論時に検出した物体のセグメンテーションや、学習前の面倒なアノテーション作業の半自動化(自動セグメンテーションで形はほぼ合っているので微調整のみになる)に活用したいと考えています。
2. 「CLIP+SAM」によるアノテーション作業の自動化構想
LAplustは、このSAMとこちらの記事で紹介したCLIPを組み合わせることで、アノテーション作業の自動化を実現したいと考えており、LAplust Eyeの機能として皆様にお届けできるように開発を進めております。
SAMは、画像内の物体をセグメンテーションすることができます。
CLIPは、同じ特徴空間上にテキストと画像をマッピングします。また、柔軟なテキスト入力に対応しています。
この2つを組み合わせることで、下記の入出力ができると考えています。
入力:物体およびその物体の特徴を表した柔軟性のあるテキスト と 物体が写った画像
出力:物体がセグメンテーションされた画像
CLIPと組み合わせることで、SAMの高精度なセグメンテーションに加えてより柔軟なセグメンテーションの実現を目指しています。
こちらの論文では、セグメンテーションを「SAM」と「SAM-CLIP」で実施しており、「SAM-CLIP」のセグメンテーションの優位性が示してありました。
下図の(1b)が「SAM-CLIP」でセグメンテーションした結果、(1c)が「SAM」でセグメンテーションした結果になります。
図を見ると、「SAM」単体より「SAM-CLIP」の方が犬をセグメンテーションできており、「SAM-CLIP」にセグメンテーションの優位性があることがわかります。
引用元:https://arxiv.org/pdf/2310.15308

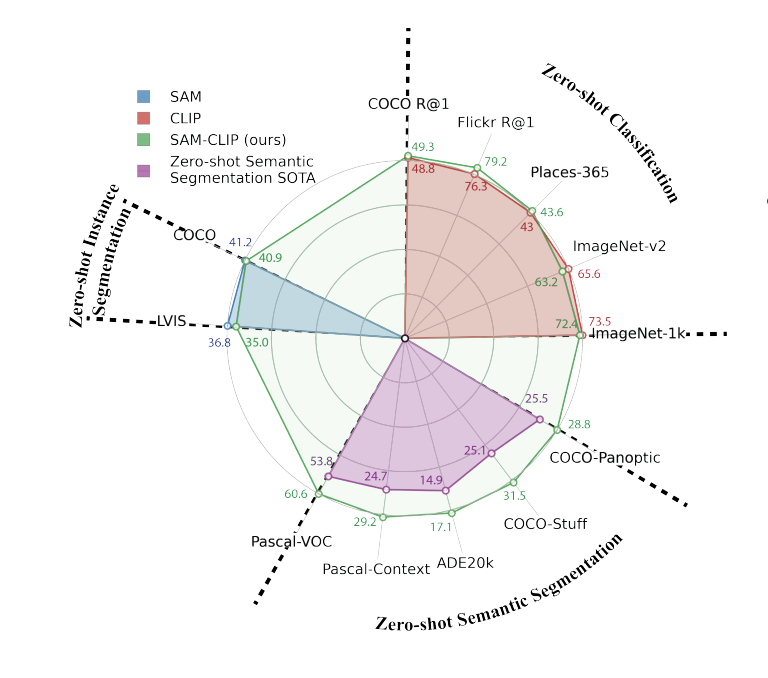
また、ゼロショットのインスタンスセグメンテーションについて、SAMのセグメンテーション能力を保持できるかを評価したものが、下図の左上:Zero-shot Instance Segmentationになります。
図を見ると、「SAM」と「SAM-CLIP」で値がほとんど変わっていないため、「SAM-CLIP」はSAMのセグメンテーション能力を保持できていることがわかります。
引用元:https://arxiv.org/pdf/2310.15308
LAplustは、学習前の面倒なアノテーション作業の自動化について、以前紹介したCLIPとSAMの組み合わせにより実現を目指しています。
CLIPはSAMに対して柔軟性を与えることできるため、物体の状態を加味したセグメンテーションが可能となり、人間が微調整・または何もすることなく、アノテーション作業を行うことができます。
そして、CLIPやSAMのような基盤モデルを活用し作成したデータセットを、より軽量なモデルで学習させることによって、AIにとって命ともいえる学習データを自動的に生成できることを目指しています。
これから実現イメージを説明します。
「CLIP+SAM」のモデルに画像とテキストを入力すると、テキストに対応した物体にセグメンテーションされた画像が出力されます。
次のような処理をイメージしています。
①セグメンテーションしたい物体(例:リンゴ)が写っている画像 と 物体の特徴まで表した柔軟性のあるテキスト を「CLIP+SAM」に入力します。
②物体がセグメンテーションされた画像が出力されます。
- 入力画像例

- 入力テキスト例
the rightmost apple
- 出力画像例
セグメンテーションされた状態で画像が出力されます。

「CLIP+SAM」が実現すると、以下のメリットが考えられます。
①アノテーション作業の時間を短縮できる
②柔軟なテキスト入力とセグメンテーションが実現できる
①:アノテーション作業の時間短縮
「CLIP+SAM」のセグメンテーション機能で形はほぼ合っているので、微調整のみ、もしくは何もしなくてもアノテーション作業が終了します。
「CLIP+SAM」は、ゼロショット精度が高いため、未知のデータに対して自動アノテーションできるポテンシャルがあり、将来的にはアノテーション作業が自動化できるようになります。
その結果、今までアノテーション作業に費やしていたリソースを有効活用できるようになります。
アノテーション作業はとても時間が掛かる作業であるため、「CLIP+SAM」により時間短縮ができると、他の業務に取り組む時間を確保できるようになることがメリットの中でも大きいと思います。
②:柔軟なテキスト入力とセグメンテーション
CLIPとSAMを組み合わせることで、SAMの高精度なセグメンテーションに加えてより柔軟なセグメンテーションが実現できるようになります。
そして、この「CLIP+SAM」により生成されたAIモデルを使用することで、サービス価値向上につながります。
サービスの価値が上がると利用者が増えます。
利用者が増えると、データが増え、最初に「CLIP+SAM」で生成されたAIモデルとは別のAIモデルが改善されます。
その改善されたAIモデルが継続的に利用されることで、AIの精度が改善されるサイクルの実現に近づきます。
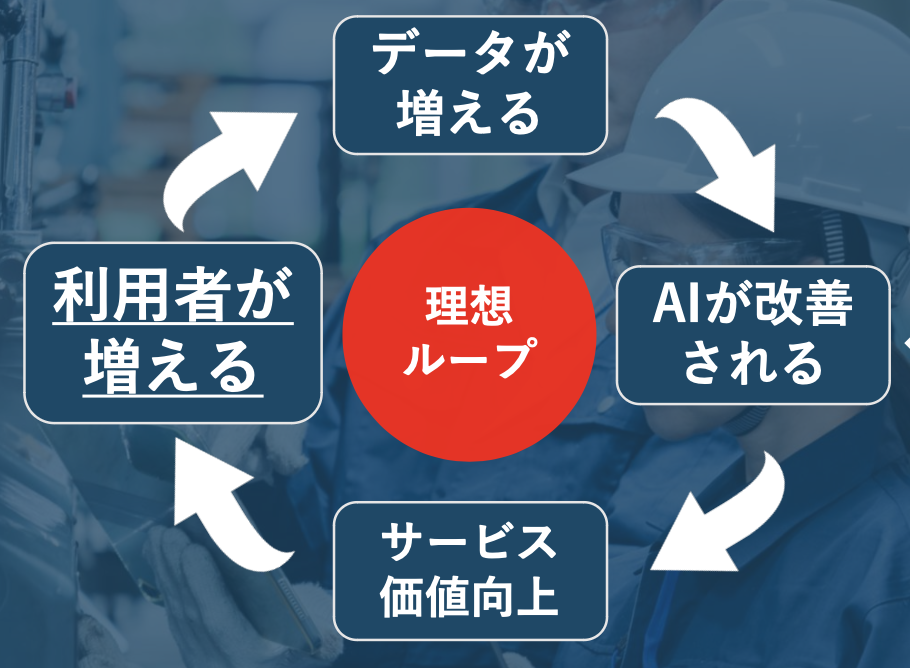
「CLIP+SAM」は、あらゆる物体に対応できるようにデータの収集と学習を進めるため、あらゆる分野において上図のサイクルを実現できるようになります。
このサイクルは、ECサイトのレコメンデーションAIのようなところでしか実現できていませんでした。
このサイクルがECサイトのレコメンデーションAI以外の分野で実現できると、ユーザーのサービス利用によって得られたデータが、そのままでは精度向上に結び付き辛い分野でも、プロダクトの品質向上のためにデータを活用できる可能性が高まります。
3. まとめ
今回のブログは、SAMという機械学習のセグメンテーションモデルについて記載しました。
SAMは、ポイントやバウンディングボックス等の入力プロンプトからオブジェクトマスクを生成し、画像内のすべてオブジェクトに対してセグメンテーションを行います。
事前に膨大な画像とマスクで構成されたデータセットでトレーニングされているため、ゼロショット学習で高精度のセグメンテーションを実現できます。
また、LAplustは今後、「CLIP+SAM」を実装し、アノテーション作業の自動化を進める構想があります。
LAplust Eyeの機能として「CLIP+SAM」の開発を進め、皆様により良い技術を提供できるよう邁進していきます。
このブログが皆様にとって有益な情報となれば幸いです。
LAplustではChatGPTをはじめとした「生成AI」の機能を飛躍的に向上させたTransformerを画像や物体検出に応用し、高精度な「人の目視と判断」を提供するLAplust Eyeを開発しております。
- 製品外観検査の省力化・省人化
- 出荷前の不良品検出
- 生態調査の半自動化
など省人化と活人化を実現したい現場の課題について声をお聞かせいただけると幸いです。
上記のような課題をお持ちであったりLAplust Eyeにご興味をお持ちいただけましたら、ぜひ、お問い合わせください。
最後までお読みいただきありがとうございました。