物体検出タスクにおけるExif情報の落とし穴
※この記事は、機械学習で推論を実施する初心者のエンジニア向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回のテーマは、「物体検出タスクにおけるExif情報の落とし穴」です。
LAplustの物体検出エンジン「LAplust Eye」は、目視の代替に特化しており、画像をカメラで読み取って物体検出を実施し、より良いサービスを提供するため改良を継続しています。
「LAplust Eye」は、画像内の物体情報を読み取り、学習を繰り返して精度を向上させるのですが、先日、学習後の結果を検証した際に、Exif問題につまづきました(・・;)
このExif問題は、皆様もつまづく問題だと感じましたので、情報共有のために技術ブログを執筆しました。
是非最後までお読みください。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. Exifデータ
2. Exifデータが機械学習に及ぼす影響
3. Exifデータの一般的な問題とその識別
4. 問題解決のためツールと修正方法
5. LAplustがつまづいたExif問題の解決
6. まとめ
1. Exifデータ
デジタル画像には見えない情報が含まれています。
この情報はExif(Exchangeable Image File Format)と呼ばれ、デジタルカメラやスマートフォンで撮影した写真に自動的に埋め込まれます。
Exifデータには、撮影日時、使用カメラのモデル、シャッタースピード、絞り値、ISO感度、GPS座標など、様々なメタデータが含まれています。
機械学習において、このExifデータはただのメタデータではありません。
特に画像を扱う際、このメタデータは画像の内容理解を深めるための重要な手がかりとなり得ます。
例えば、撮影された環境の光条件や位置情報から、画像のコンテキストを把握し、より精度高い推論が可能となります。
しかし、これらの情報が完全であるとは限りません。
時にはExifデータが欠損していたり、誤った情報が含まれていたりすることもあります。
これらの問題をどのように特定し、対処するかが、機械学習モデルの性能を左右するカギとなります。
2. Exifデータが機械学習に及ぼす影響
機械学習で画像を扱う際、Exifデータは重要な役割を果たします。
以下ように、Exifデータは機械学習において多面的な影響を及ぼします。
画像の前処理におけるExifデータの利用
機械学習モデルを訓練する前には、画像データの前処理が必須です。
Exifデータは、画像がどのように撮影されたかの詳細を提供する役割を担っています。
例えば、Exifデータから得られる撮影時の光の条件やカメラの設定は、画像の自動調整に役立ちます。
さらに、画像の向き(ポートレートまたはランドスケープ)を自動で正しい方向に調整するのにも使用されることがあります。
推論精度の向上
Exifデータに含まれる地理的情報や撮影時間などのメタデータは、画像のコンテキストを理解する上で非常に価値があります。
例えば、ある地域特有の植物を識別する機械学習モデルを開発する際、GPSデータを利用してその地域の典型的な植物かどうかを判断する補助情報として使うことができます。
また、撮影時間によっては、画像の照明条件が推論結果に影響を与える場合があり、その調整にも役立ちます。
問題点の認識
しかし、Exifデータの利用には注意が必要です。
データが不完全であったり、間違った情報が含まれていたりすることがあります。
これらの誤情報は、誤った前提に基づいたデータ処理を引き起こし、結果としてモデルの推論精度を低下させる可能性があります。
そのため、データの検証と情報整理は、利用前の重要なステップとなります。
学習を行う前に利用するデータを注意深く観察していくことが重要です。このステップをおろそかにすると、思わぬ落とし穴にはまってしまいます。
3. Exifデータの一般的な問題とその識別
Exifデータは画像ファイルに多くの有用な情報を提供しますが、これらの情報は常に完璧ではありません。
Exifデータの問題を効果的に識別し、対応することで、機械学習の精度と信頼性を向上させることができます。
よくある問題点
- データの欠損: Exifデータは、特に古いデジタルカメラや一部のスマートフォンアプリでは不完全なことがあります。
重要なメタデータフィールドが空欄であるか、全く含まれていない場合があります。 - 誤った情報: ハードウェアの誤設定やソフトウェアのバグにより、時刻や位置情報など、不正確なデータがExif情報に含まれることがあります。
これが推論に誤ったコンテキストを提供し、結果の精度を損なうことにつながります。 - プライバシーの問題: 位置情報や個人を特定できるデータが含まれることがあり、これらのデータの扱いには注意が必要です。
不適切な情報の公開はプライバシー侵害につながることがあるため、データの匿名化や消去が重要です。
問題の識別方法
Exifデータの問題を効果的に識別するには、以下の手順を踏むことが勧められます。
- データの検証: Exifデータを機械学習モデルに組み込む前に、内容を精査します。
Pythonなどのプログラミング言語を使用して、データが存在するか、そしてそれが合理的な範囲内であるかを確認します。 - データクレンジング: 問題が識別された場合、データの修正や削除を行います。
例えば、誤った時刻データは修正するか、そのデータを持つ画像をデータセットから除外することがあります。 - セキュリティ対策の適用: プライバシーに関する懸念がある場合は、Exifデータから個人情報を削除または匿名化します。
4. 問題解決のためツールと修正方法
Exifデータの問題を識別した後は、それらを効果的に解決する手段を講じる必要があります。
以下のツールの利用と修正方法を活用することで、Exifデータの問題を効率的に解決し、機械学習の品質と精度を保証することができます。
Exifデータの操作に便利なツール
- PythonのPillowライブラリ: PillowはPythonで最も一般的に使用される画像処理ライブラリの一つで、Exifデータの読み取り、編集、削除が容易です。
- ExifTool: ExifToolは非常に強力なコマンドラインアプリケーションで、画像ファイルからExifデータを読み取る、編集する、または削除することができます。
特に大量の画像ファイルを扱う場合に効果的です。 - ExifRead: Python用の軽量ライブラリで、画像ファイルからExifデータを読み取るために特化しています。
問題の修正方法
- データの修正: 誤ったExifデータを発見した場合、適切な値に修正することが推奨されます。
例えば、誤った撮影日時が記録されている場合、他のソースから正しい情報を取得し更新します。 - データの除外: 修正が不可能または非効率的な場合、問題のあるデータを持つ画像をデータセットから除外する選択肢もあります。
- プライバシー保護: 個人情報が含まれるExifデータは、プライバシー保護の観点から削除または匿名化する必要があります。
ExifToolなどのツールを使用して、これらの情報を安全に処理します。
5. LAplustが直面したExif問題の解決
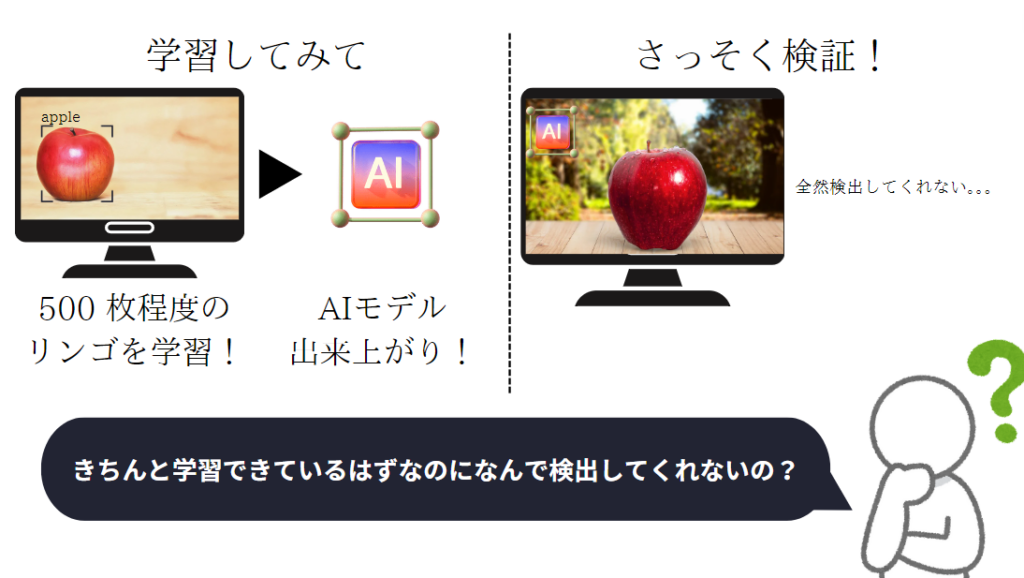
LAplustがExif問題に直面したのは、画像内の物体情報の学習を行い、学習の結果が正しいのか検証した時です。複数枚の検証画像で物体を全く検出しないという問題が起こりました。
ここでは例として、検出したい物体は「リンゴ」として話を進めます。
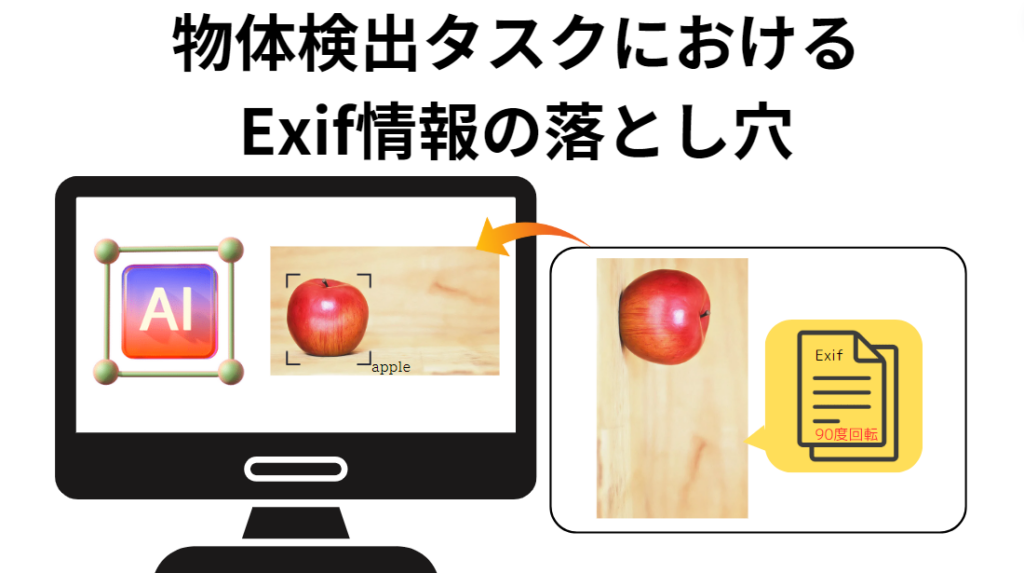
結論からいうと、原因は、利用したアノテーションツールと、学習に使用したLAplustのシステムの画像読込仕様の差異でした。
具体的に記述します。
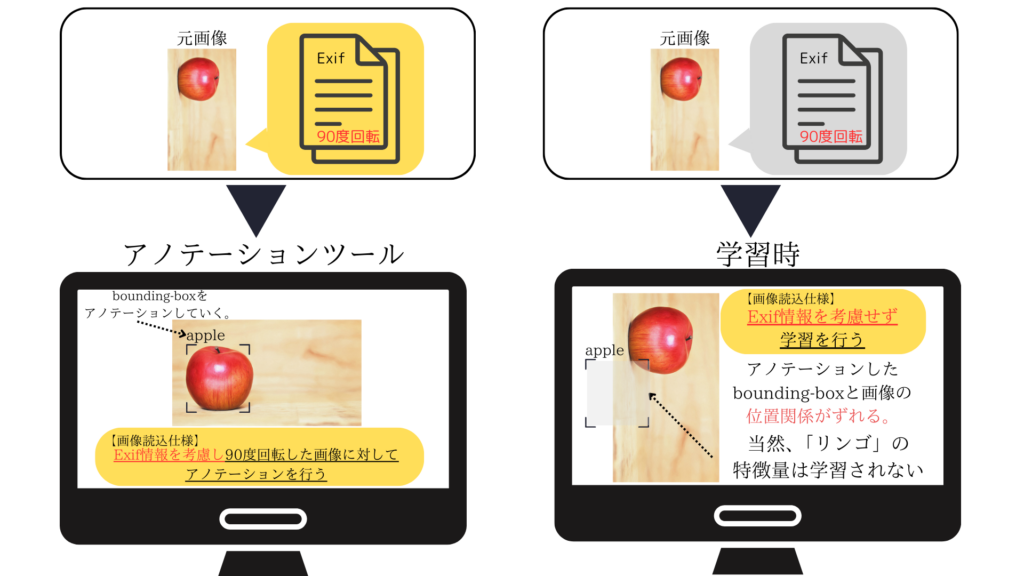
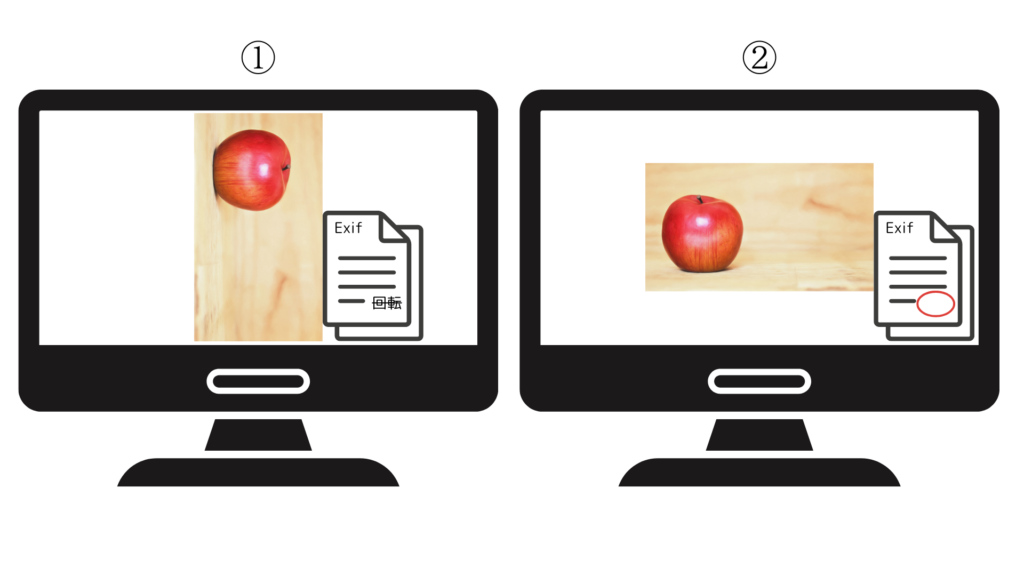
アノテーションツールの画像読込仕様は、Exifデータを考慮し画像を表示するというものでした。(Windowsの場合、Exif情報の「向き」に「90度回転」という情報が含まれている場合は、その情報を考慮して元画像を反時計回りに90度回転して表示する仕様)
一方で、学習を行う際のシステム側の画像読込仕様は、画像を回転するExifデータがあったとしても、画像の正位置を統一させ表示するシステムとなっていました。(Windowsの場合、Exif情報の「向き」に「90度回転」という情報が含まれている場合でも、元画像の回転状態(標準)で表示する仕様)
上記の図のようにリンゴをアノテーションする際には、元画像に対してExifを考慮し、画像内のリンゴの座標(x,y)を示すbounding-boxが作成されます。しかしながら、学習時は元画像に対してExifを考慮しないため作成済みのbounding-boxと読み込んだ画像の位置関係がずれます。
学習する際は、
「画像」の上に、先ほどリンゴをアノテーションした際に生成されたbounding-boxを重ねて、リンゴの特徴量を学習します。
しかし、学習時の画像は、Exifを考慮しない『元画像』で読み込まれるので、その上にbounding-boxが重ねられると、下図のようにリンゴとは関係のない場所を一生懸命学習します・・・
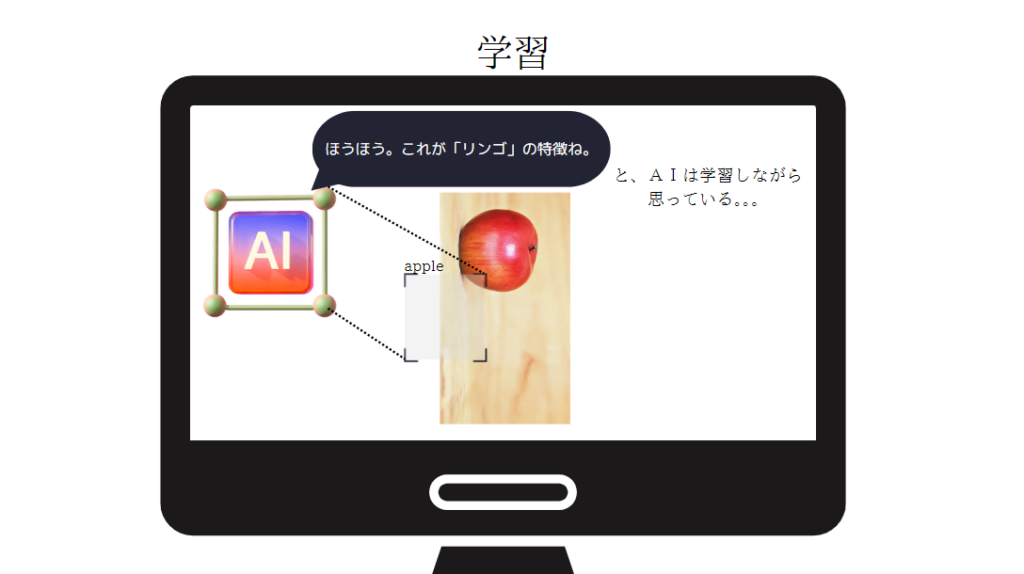
したがって、当然のことながら、AIはリンゴの特徴量を学習できず、検証段階で全く検出してくれなかったというわけですね。
本来であれば、アノテーションツールと学習システムで、表示される画像の向きが同じにならないといけません。
しかし今回のケースでは、画像読込仕様の差異でアノテーションツールと学習システムで、表示される画像の向きが90度違っていました。
結果、このような学習を行ったため、学習後の検証段階で、検証データとして準備したリンゴが映った画像にて「リンゴ」を検出しない状態となっていました。
ここまで読んでいただいた方で勘の鋭い方はお気づきかもしれませんが、
「学習システムでもアノテーションツールと同じようにExif考慮すればいいじゃん!」
と思われるかもしれません。さすがです。このあたり深い深い理由があり、意図して現状の学習システムの仕組み(Exifがあった場合でも読み込み時の正位置で統一)になっています。このあたりの理由はシステム全体の設計思想やAI業界全体としての考え方が深く関連するところなので別記事で紹介します。(※2024/05/02時点で準備中)

今回、Exif問題の対策として、学習前のデータ読み込み時に、画像を回転するExifデータが格納されている場合は注意喚起を行う前処理を導入しました。
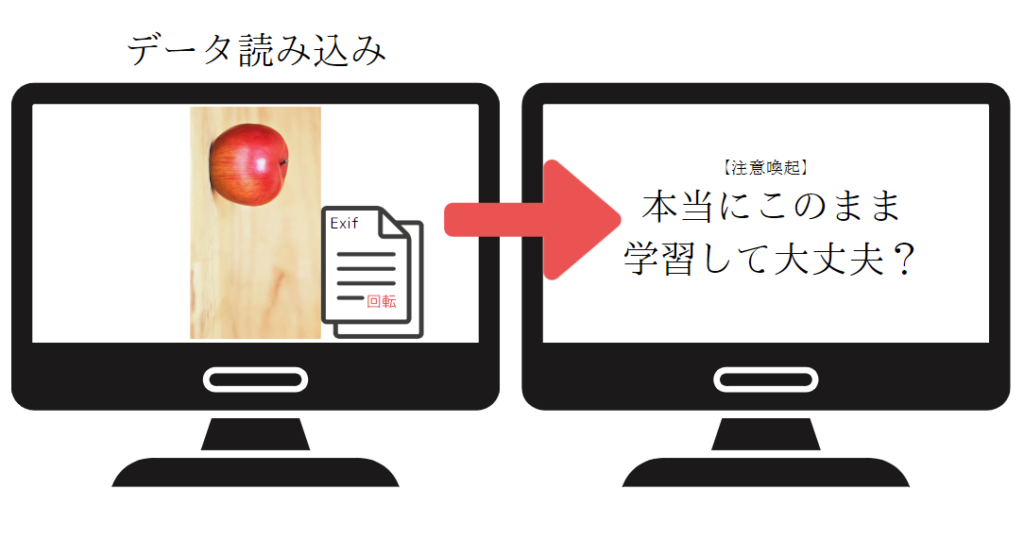
これで同じ落とし穴にはまることはなくなるわけですね。
なお、今回のケースでは、
Exif情報は不要でしたので、冒頭に述べたようなツールを使用し下記の対応を実施するようにしました。
①Exifデータから画像回転情報(「向き」)を削除
②画像編集を実施(画像回転情報と同様の回転を行い保存)
→これまではExif情報によって画像の回転角度を決定していたが、Exif情報に記載の通りに画像編集を実施し、「Exif情報を不要にした」ということです。これで「原因」は解消されます。
その後、再度データ読み込みを行い、学習するようにしました。
この対策を講じたことにより、今後はExif問題を考慮した上で、学習と検証を行えるようになりました。

めでたしめでたしー!
6. まとめ
Exifデータは機械学習において精度に大きく影響します。
LAplustが直面したExif問題を通して、Exifデータを考慮した前処理がより一層重要だと感じたのではないでしょうか。
Exifデータというパッと見では目に見えない情報が機械学習に与える影響も考慮の上、エンジニアリングできるようになることを願っています。。。(すごくニッチな考慮点ですがむちゃくちゃ重要です。)
このブログが皆様にとって有益な情報となれば幸いです。
LAplustではChatGPTをはじめとした「生成AI」の機能を飛躍的に向上させたTransformerを画像や物体検出に応用し、高精度な「人の目視と判断」を提供するLAplust Eyeを開発しております。
- 製品外観検査の省力化・省人化
- 出荷前の不良品検出
- 生態調査の半自動化
など省人化と活人化を実現したい現場の課題について声をお聞かせいただけると幸いです。
上記のような課題をお持ちであったりLAplust Eyeにご興味をお持ちいただけましたら、ぜひ、お問い合わせください。
最後までお読みいただきありがとうございました。