MLOpsの課題と解決策
※この記事は、MLOpsに関心があるが経験が浅い初心者向けとなります。
皆さん、こんにちは!
LAplustの中村です。
今回のテーマは、「MLOpsの課題と解決策」です。
LAplustの物体検出エンジン「LAplust Eye」は機械学習を行っており、現在社内ではMLOpsの導入を進めています。
MLOpsは、機械学習を取り入れたシステムの開発・運用を円滑に行い、迅速かつ安定したサービスをお客様に届けるための考え方やその手法です。
LAplustはMLOpsを実践し、単なる機械学習エンジンの提供ではなく、AIやITに詳しくなくとも機械学習を「便利な道具」として現場に取り入れるための工夫を行っております。
そうすることで昨今社会課題となっている人手不足の解消や生産性の維持/向上に課題を持たれている皆様に広く使っていただけるようになることを目指しています。
これからMLOpsの課題と解決策、LAplustでの実践について記述します。
是非最後までお読みください。
※一部の文章を生成AIによって生成しています。内容の誤り等がないよう細心の注意を払っていますが、万が一お気づきの場合はご指摘いただけますと幸いです。
目次
1. 背景
2. MLOpsとは?
3. MLOpsの主な課題
4. MLOps解決策
5. LAplustが実践しているMLOps
6. まとめ
1. 背景
機械学習を社会実装する上では、様々な課題があります。
例として「データ収集に時間がかかる」や「システム構成が複雑となる」等が挙げられます。
これらの課題に早めに向き合い、対処していくことが、コストを抑えることに繋がります。
そのため、機械学習を効率的かつ効果的に展開し運用する方法は、現代社会において重要となっており、MLOpsを導入することが広く求められるようになりました。
MLOps(機械学習運用)は、機械学習のライフサイクルを通じて品質とスピードを向上させる考え方やその手法を指します。
これは、ソフトウェアの開発と運用の最適な方法を機械学習プロジェクトに適用することで、開発からデプロイメント、モニタリング、メンテナンスに至るまで、プロセス全体をスムーズかつ効率的にすることを目的としています。
ここが一番のポイントとなります。
『機械学習のプロジェクトで注目される「AIモデルを実装する」は「AIをサービスとして現場に提供する」上での一つの要素に過ぎないことをまずは理解する』ことが重要です。
「AIをサービスとして現場に提供する」ことは、AIモデルを実装すること以外にも実は下図のように山のようにやることがあります。
引用元:https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning?hl=ja
MLシステムの要素
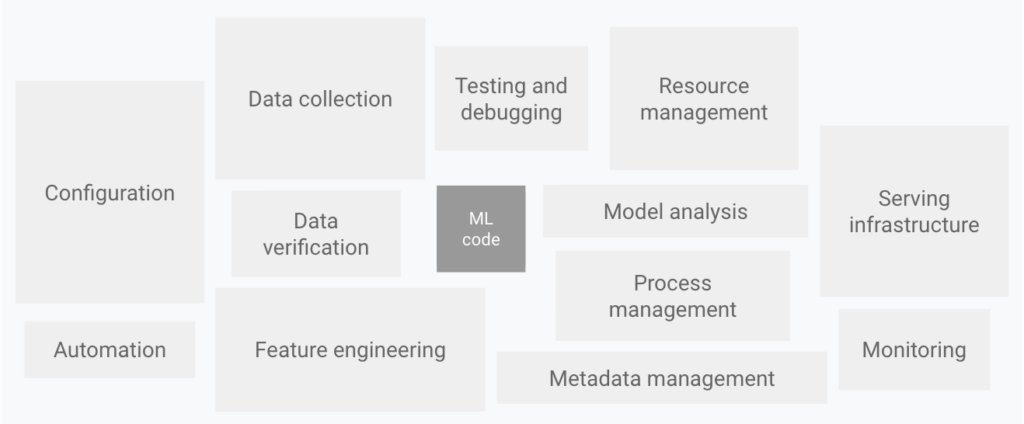
各要素の四角の面積が広いほど、コストが掛かります。
機械学習コード(AIモデル)の周りには、データ収集やデータ検証、テストとデバッグ、モデル解析等、様々な要素があり、AIモデルの実装は機械学習システムの中でほんの一部であることがわかります。
機械学習のプロジェクトではこれらの要素を効率的に運用する手法が必要になります。
2. MLOpsとは?
前章で述べた機械学習システムの要素を効率的に運用する考え方や手法がMLOpsです。
MLOpsとは、「Machine Learning Operations」の略で、ソフトウェアエンジニアリングの原則と方法論を機械学習の開発と運用に適用する方法です。
その目的は、機械学習モデルの開発、デプロイメント、モニタリング、メンテナンスを効率化し、これらのプロセスを自動化することで、高速で信頼性の高い機械学習システムの提供を可能にすることにあります。
MLOpsの重要性
MLOpsの導入は、機械学習プロジェクトにおいて次のような多くの利点をもたらします。
- 再現性: データ、モデル、コードのバージョン管理を通じて、結果の再現性と透明性を保証する。
- 拡張性: モデルのトレーニングとデプロイメントの自動化により、複数のモデルや大規模なデータセットを効率的に処理できる。
- 共同作業の向上: 機械学習チームと開発チーム、運用チームの緊密な連携を促進し、プロジェクトのスムーズな進行を支援する。
- 品質保証: 継続的なテストとモニタリングにより、モデルの品質とパフォーマンスを維持し、改善する。
MLOpsとDevOps
MLOpsはDevOpsから発展した概念であり、ソフトウェア開発と運用の統合に焦点を当てたDevOpsの原則を機械学習プロジェクトに適用します。
しかし、MLOpsは、モデルのトレーニング、データの品質、モデルのパフォーマンスモニタリングなど、機械学習特有の課題に対処するために特化した方法を含んでいます。
MLOpsの導入により、機械学習モデルのライフサイクル全体を通じて、より迅速かつ効果的に価値を提供することが可能になります。
MLOpsのフレームワーク内で、モデルの開発からデプロイメント、メンテナンスまでのプロセスをスムーズに進めることができ、目標の達成に向けた機械学習の活用を加速させることができます。
3. MLOpsの主な課題
以下は、MLOpsを導入する過程で直面する主な課題です。
モデルのデプロイメントの複雑さ
機械学習モデルを開発環境から実稼働環境に移行する過程は、技術的な複雑さに満ちています。
モデルがトレーニングデータに対してうまく機能しても、実際の環境で期待通りに動作するとは限りません。
このギャップを埋めるためには、モデルのパフォーマンスを正確に測定し、継続的に監視する必要があります。
CI/CDの実装
引用元:https://jp.community.intersystems.com/post/aws環境を用いたcicdの仕組みの紹介。
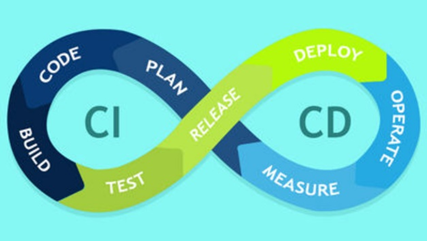
継続的インテグレーション(CI)と継続的デリバリー(CD)は、ソフトウェア開発プロセスの自動化と効率化を促進しますが、機械学習プロジェクトにこれらを適用することは大変な作業になります。
データの品質、モデルの精度、依存関係の管理など、考慮すべき追加的な要素が多く、これらのプロセスを自動化するための戦略を練る必要があります。
データとモデルの管理
機械学習プロジェクトは、高品質なデータに大きく依存しています。
データの収集、前処理、バージョン管理は、プロジェクトの複雑さを増大させます。
さらに、トレーニング済みモデルのバージョン管理も、モデルの改善と追跡のために重要です。
パフォーマンスモニタリング
モデルがデプロイされた後も、そのパフォーマンスを継続的に監視し、変化するデータや環境条件に対応して適時に更新する必要があります。
これには、効果的なモニタリングツールと、パフォーマンスが低下した場合の迅速な対応計画が必要となります。
4. MLOps解決策
MLOpsの導入を進める上で直面する課題は多いものの、これらを克服するためのツールやアプローチが存在します。
以下は、MLOpsの基本的な課題に対処するための実践的な解決策です。
自動化とオーケストレーション
- Kubernetes: コンテナオーケストレーションのためのオープンソースシステムで、アプリケーションのデプロイメント、スケーリング、管理を自動化します。
Kubernetesを利用することで、機械学習モデルのデプロイメントを簡単にかつ一貫性をもって行うことができます。 - Airflow: データパイプラインのスケジューリングとモニタリングを自動化するオープンソースツール。
データ処理タスクの依存関係を管理し、複雑なワークフローを簡単に構築できます。
バージョン管理
- Git: ソースコードのバージョン管理システムで、モデルのコードや実験の追跡にも適用できます。
Gitを活用することで、チームメンバー間での共同作業が容易になり、変更履歴の追跡が可能になります。 - DVC (Data Version Control): データセットと機械学習モデルのバージョン管理を専門とするオープンソースツール。
大規模なデータセットのバージョン管理と、データパイプラインの管理を簡単にします。
パフォーマンスモニタリングの戦略
- Prometheus: オープンソースの監視ツールで、リアルタイムの監視とアラートを提供します。
機械学習モデルのパフォーマンス指標を追跡し、異常が検出された場合にアラートを送信できます。 - MLflow: 機械学習ライフサイクルの管理を支援するオープンソースプラットフォーム。
モデルのパッケージング、デプロイメント、パフォーマンスモニタリングのための統合的なフレームワークを提供します。
5. LAplustが実践しているMLOpsの具体例
LAplustでは、こちらの記事で紹介した「DETR」や「YOLOX」、またこちらの記事で紹介した「DETRのセグメンテーションモデル」等の複数の機械学習モデルを取り扱っています。
機械学習を使用したシステム開発・改修は今後、MLOpsを整えていかないと立ち行かなくなるという危機感があり、当然社内でもMLOpsの実践を進めています。
MLOpsは機械学習開発・提供活動全般にわたるテーマなので、ここでは、その具体例として、「機械学習モデル」と「重み」のフォーマット変換に関する取り組みをご紹介します。
初めに、機械学習モデルのフォーマット変換を試みました。
この時、ONNX(オニキス)と呼ばれるフォーマットを選定しました。
機械学習モデルのフォーマットが統一されれば、様々なフレームワーク間で機械学習モデルを使用することができるようになります。
例えば、PyTorchというフレームワークを用いて学習させた機械学習モデルは、Tensorflowというフレームワークで推論させる際に、そのまま使用することはできません。しかし、機械学習モデルのフォーマットをONNXに変換すれば推論が可能となります。
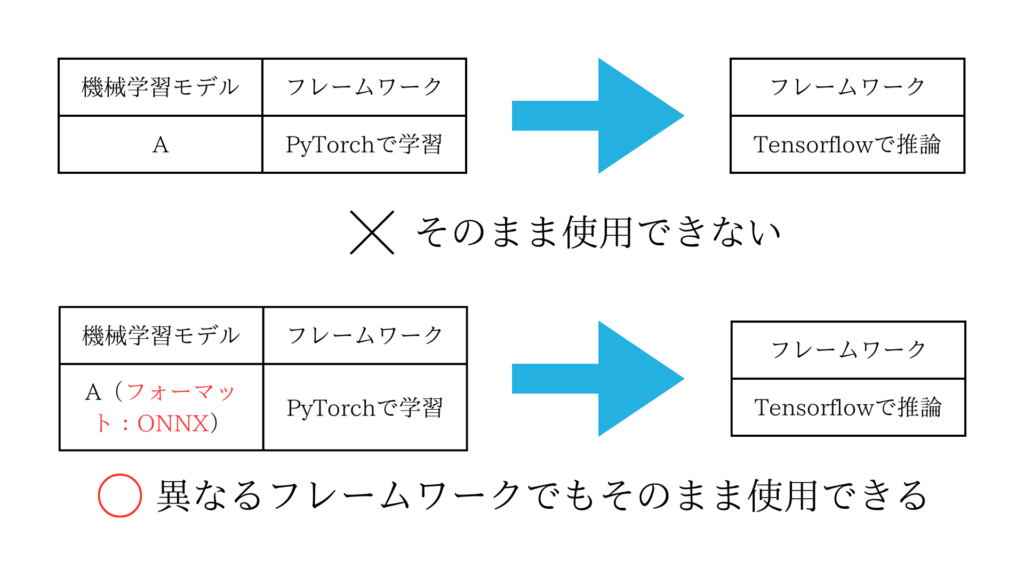
このONNXのフォーマット変換を進めていましたが、①、②の理由から別の方法を探しました。
①TensorFlowからONNXに変換する「tf2onnx」というライブラリは、割とアクティビティが盛ん(最新リリース:2024/1/16)だが、コントリビュータが少なく、ONNXやTensorFlowのアップデートに追従するのが厳しそうに見えること
②ONNXからTensorFlowに変換する「onnx-tensorflow」というライブラリは、一般的な手法だったがメンテナンスに消極的であること(最新リリース:2022/3/18)
また、世界的に有名なHuggingFaceという機械学習モデルの開発と共有、公開をするためのプラットフォームでは、1つ機械学習モデルをPyTorchとTensorFlowの2つ実装した上で、一方で学習した重みをもう一方に変換するという手法を採用しているものもありました。
ここで、PyTorchとTensorFlowそれぞれの利点を考えると、次の表のようになります。
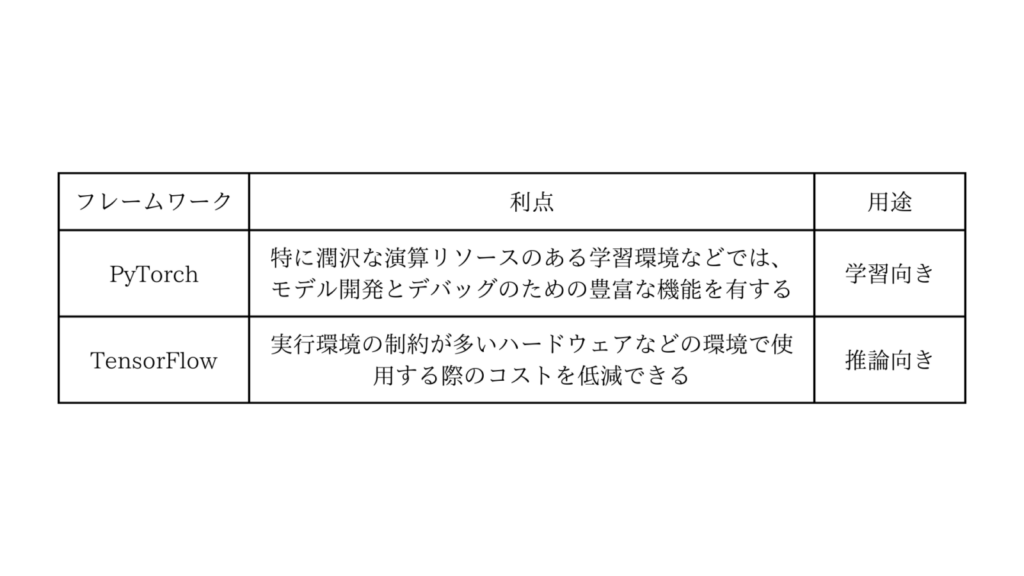
この利点を活かすために、各機械学習モデルでPyTorchとTensorFlowのそれぞれを実装し、PyTorchで学習した重みをTensorFlowに変換するという方針へ変更しました。(モデルは変換せず、重みのみ変換する)
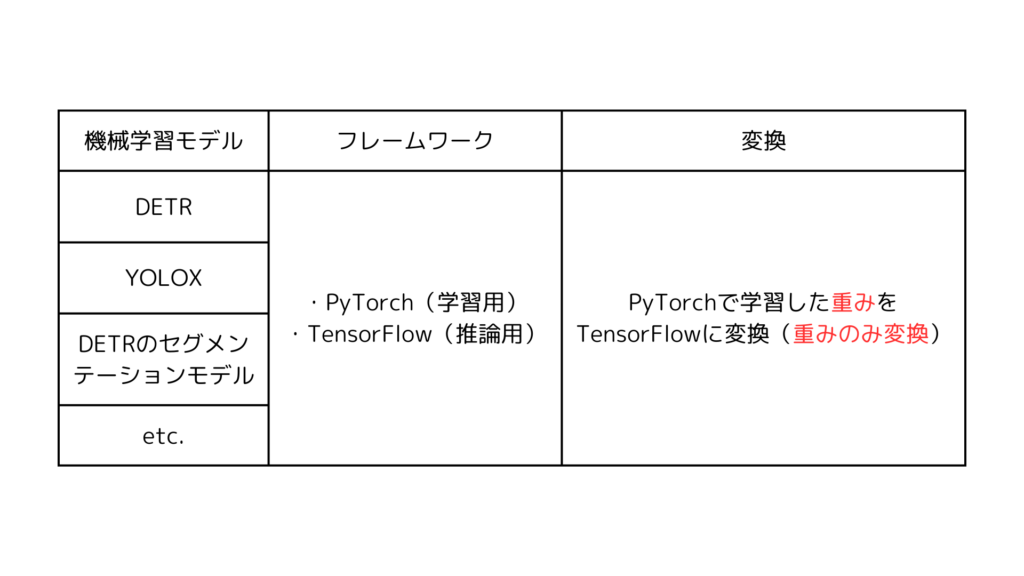
このようにLAplustでは、各機械学習モデルでフレームワークと重みの変換の統一を実践することで、MLOpsの観点でいうと、データとモデルの管理コストや、開発とメンテナンスのコストの大幅な削減につながっています。
現在、各機械学習モデルでPyTorchとTensorFlowのそれぞれを実装している最中であり、「保守性」、「再現性」、「可用性」を考えながら進めているので、とても苦労しています。
- 保守性: 複数のモデルを1つのプログラムで統合して利用できるようにすることで、従来のモデルも利用できる状態を保ちながら、新たなモデルの追加・新規プロジェクトへの適応を目指していますが、目まぐるしく変化する深層学習技術を1つのプログラム内で保守性を保ちながら実装することは容易ではありません。
現在LAplustは、将来的に実現しようとしている「高生産性栽培ハウス」で利用できる技術醸成が必要なので、その場限りでしか使えないプログラムは作らないようにしています。 - 再現性: 機械学習は膨大な演算のもとで成り立っており、全ての演算が最終的な出力に影響しているので、出力結果の違いの原因箇所の特定が非常に困難です。
特定のモデルが存在したとして、そのモデルが「いつ」「どこで」「どうやって」作成されたものかを管理できていなければ、まず再現できません。
また、再現するにも「学習」「評価」「推論」など複数の対象が存在し、「学習」したものをちゃんと「評価」するには、「学習」と同じ前処理を施したデータを同じニューラルネットワークに投入し、その結果は同じ後処理を施す必要があります。
ただ、「学習」時のデータは様々な汎化性向上のための処理が施されているので、ただ同じ前処理を使うだけでは正しく「評価」できません。
そして、「推論」においてはさらに注意が必要で、「推論」で投入されるデータは、「学習」や「評価」で使用したような綺麗なデータではなく、画像データにおいては、回転していたり、画像フォーマットが違ったり、色補正されていたりしています。
画像サイズもさまざまなので、ニューラルネットワークで扱えるサイズにリサイズしたりする必要があります。
しかし、このリサイズ時に、アンチエイリアス(斜線や曲線などに発生する微細な階段状のギザギザした部分(ジャギー)を目立たなくする手法)の使用有無、リサイズのアルゴリズムに何を使うかでも最終的な演算結果が異なってきます。 - 可用性: 特定のモデルを使えるプログラムを構築して、維持していかなければならず、新たなモデルを導入する際の実装が、既存のモデルに悪影響を与えないようにすることが必要であり、また既存モデルの実装が、新たなモデル導入の妨げになってはいけません。
その新たなモデルの仕様が一貫していれば良いですが、斬新で革新的なアルゴリズムが日々生まれている機械学習分野において、実装やアルゴリズムレベルでの仕様が策定されることはまずありません。
そのようなものをプロダクトのシステムに導入するという難しさがあります。
上記のように商用レベルで機械学習を実践しようとすると一筋縄ではいかないことが多々ありますが、幸いにも海外の先端的なMLOpsの実践企業が情報発信を積極的に進めています。
そのため、弊社としては次々に吸収して実践していくことが可能になっており、LAplustもまたMLOpsの実践例を皆様に共有していくことが機械学習の実践を社会全体で推し進めるうえでの重要なアクションと考えこの記事を記載しています。
6. まとめ
このブログでMLOpsに対する理解が深まったのではないかと思います。
LAplustの実践を記載していますので参考にしていただき、皆様もMLOpsの導入を一歩ずつ進めてみてはいかがでしょうか。
LAplustではChatGPTをはじめとした「生成AI」の機能を飛躍的に向上させたTransformerを画像や物体検出に応用し、高精度な「人の目視と判断」を提供するLAplust Eyeを開発しております。
- 製品外観検査の省力化・省人化
- 出荷前の不良品検出
- 生態調査の半自動化
など省人化と活人化を実現したい現場の課題について声をお聞かせいただけると幸いです。
上記のような課題をお持ちであったりLAplust Eyeにご興味をお持ちいただけましたら、ぜひ、お問い合わせください。
最後までお読みいただきありがとうございました。